


OpenAI o3 vs. o4-Mini-High vs. Gemini 2.5 (April 2025 Review)
Giving you my opinions on new AI's in April 2025...

Many AI analysts and microbloggers on X flood the internet with nothing but hype-spam after every little AI tweak/update… minor update? OMFG! Feeling the AGI!… blah blah. (Not to discredit those doing a legitimately good job… rarefied air… few.)
Perhaps the stupidest hype award goes to when Operator and/or Sora were released; who uses these other than for Twitter/X likes? I don’t know what’s gotten more nauseating: AI hype circle jerks by influencers or finance experts on X posting GPT-slop threads and getting thousands of likes.
(To be fair, many people fall for AI slop — have seen morons and high IQs alike not realize certain posts are AI. There are cues but maybe some people have a blind-spot lacking the detection mechanisms to see the word “delve” or specific “punchy” phrasings… Example (courtesy of GPT-4o: “They’re not missing the signs. They’re missing the sensors.”) Lmao.
I guess the AI works and it’s low effort… churn out slop, people eat it up like farm animals out of a trough… I understand the grindset. Churn churn churn. Hustle Hustle. Marketing. Maybe will write another article about the insidious trend of AI slop posting/drift (TBF, AI slop may be better than what most posters could do on their own… so net improvement? Just has a bizarrely off-putting vibe; AI-misographia.)

This week has been nothing but an AI hypenado. What warranted the hype? Everyone has been waiting on OpenAI’s new o3 model since announced in late-December 2024. Breakneck pace scaling up the abilities — en route to rendering human cognition irrelevant?
I’ve never left the OpenAI bandwagon. Everyone has been trying to manufacture drama re: Sam Altman and co. just because OAI stays kicking everyone’s ass and they don’t want to compete — it’s a jealousy thing. (Meta, DeepSeek, Grok, et al.)
Nothing against open source, it has its place… but if you want to actually compete for the throne… you aren’t open sourcing unless it’s a gov initiative subsidized by the CCP to undermine U.S. AI competitiveness (e.g. DeepSeek).
There’s a reason Elon and Zuck are doing everything they can to smear OpenAI (Grok isn’t yet in the lead, Llama is irrelevant, etc.). Am hoping OpenAI decimates any lawsuits thrown their way in obvious attempt to slow their progress.
There’s no moat? At this point if you think there’s no moat you are braindead. Go use a shitty AI product. Oh I thought no moat? The moat is and always has been ability & time. The latency between the #1 spot and #2 spot is the moat. Other things like user experience and uncensored/low censorship matter too — but the moat is “Are you the best?” The same people claiming no moat also want the best models for free… if there were no moat they would be free.
It’s the same predictable ramblings from AI commentators: (1) tHeRe’S nO mOaT!; (2) OpEnAi iS dYiNg! (All the best talent left! They’re toast!) Scam Altman!; then (3) Wow! ChatGPT is really good! I guess I’ll keep using it!
Can’t take 99% of these idiots seriously. If there’s no moat why do you keep using ChatGPT? Lol. Oh the Grok 3 model is better? Thanks for telling me you work at xAI or are hoping Elon retweets/reposts your post on “X.”
Past AI Hype that was Warranted…
Reflecting on the evolution of AI since I’ve been using it… ChatGPT-3.5 was a game-changer for certain types of tasks. Not great but useful in some ways.
GPT-4o: Still great. Has been updated a few times, but an all-around powerhouse for your average person.
Reasoning models: ChatGPT dropped first (o1-preview paved the way)
Cost-efficiency improvements: DeepSeek-R1, Gemini, etc.
Claude: Coding & consistent accuracy. Censored like a mf… but whatev. I don’t use it. Assume it’s good but unless it levels up, no point.
o1-pro: Game-changer when it dropped. My most-used model by far.
Grok 3: A vibe when it dropped. Even if it wasn’t “the best” it was addictive and improved rapidly. Was my fav for a 2-3 week stretch. Still use it a lot for its low censorship and X analysis. Accuracy is good too. (Read: Best Low Censorship AIs 2025 & Maximum Truth Seeking AI vs. Woke Filters)
What about image generation? Decent for a while but no basic “infographic” capabilities. Would fumble the text and you’d get some triple letters and Russian symbols. Now it can make basic infographics and the anime Studio Ghibli trend went viral. Big upgrade in 2025 via ChatGPT.
Eventually it’ll be able to make a detailed/complex infographic in like 3 seconds. Still a lot of room for improvement in speed, precision/accuracy, and complexity.
What about internet search integration? Until now (April 2025), Perplexity Pro curb stomped the competition. Why? It’s engineering and the fact that you can always switch to the best AI model via integration interface. It’s still very good. But the search built-into ChatGPT was horrendously bad, then improved a bit… and now it’s really good. In the past I hated it so much I wished there had been a way to manually disable internet connectivity instead of tacking on “don’t use the internet” for half my prompts. (Read: ChatGPT’s forced internet search sucks)
Well here we are in April 2025… and AI is really good. All the morons are still debating whether this is “AGI” or a “feel the AGI” moment. I’ve noted that AGI is subjective and unless you have a consensus criteria — morons will continue debating because they each have a subjective criteria that differs from everyone else’s.
By my definition we’ve had AGI for a while. (Read: AGI? Depends Who You Ask.) I could certainly come up with a ridiculous standard and say we haven’t yet achieved AGI because AGI needs to be at least 5 standard deviations smarter than Terrance Tao.
Are ChatGPT’s o3 & o4-mini-high models worth the hype?
Yes. For me they are. I’m not going to attempt to convince you that o3 is elite and currently the best model anywhere. I think it is. You are free to disagree maybe it’s not the best for you. I’m gonna give you my pure vibes impressions of each AI model that I use on a daily basis in April 2025.
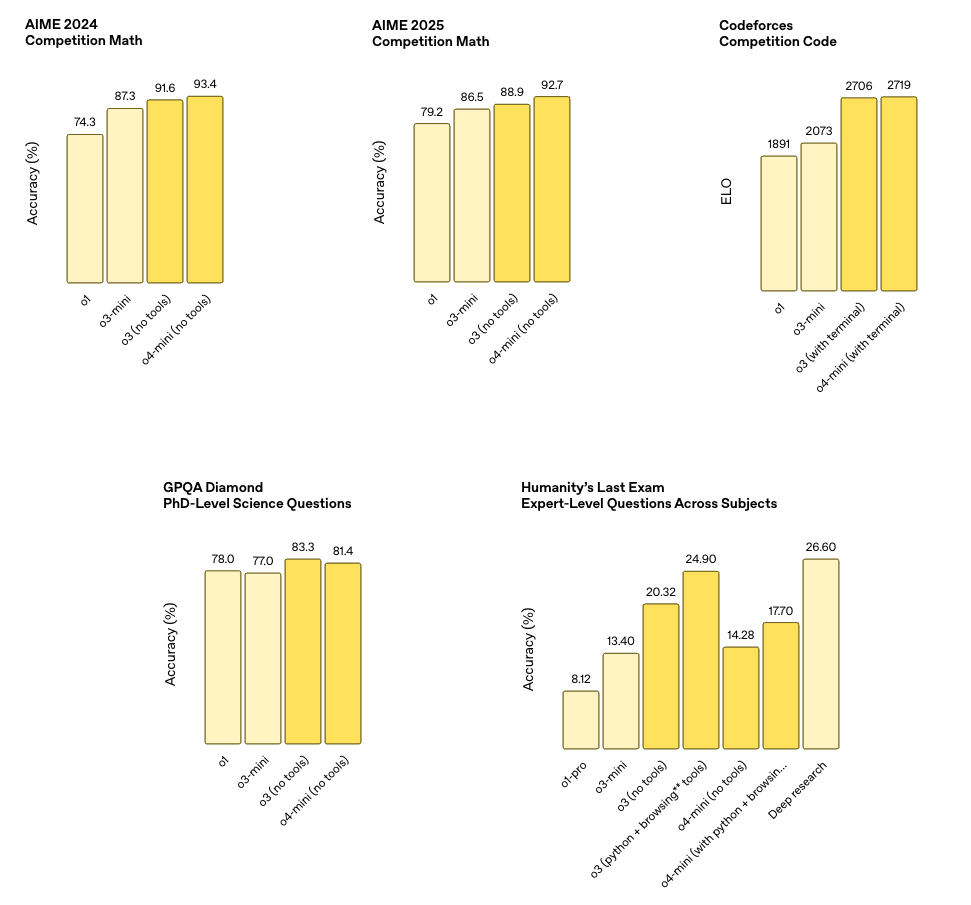
o3: Tour-de-force (Current Best)
The first model that legitimately feels like having a rapid-fire PhD research scientist in my pocket. Does it make errors? Yes. I’ve caught it hallucinating already in various “Deep Research” reports AND in general queries.
Examples: It erred on seedings of this upcoming NBA playoffs AND completely fabricated a person’s job position for another article I’m writing.
It’s super fast, searches/scans the internet similarly to the way I would research an advanced topic without AI, etc. The general model is a tour-de-force. I’ve compared my general conversations with o3 to o3 + deep research — and often times I think my own convos yield better reports than its deep research reports.
How is this the case? Because it researches one specific query at a time — then can focus on an entirely new topic. I’m still impressed with the deep research combined with o3 though.
Better than o1-pro? Everything considered? Yes. BUT!!! I still think o1-pro has a couple highly-specific advantages (longer outputs, lack of internet connectivity, organizing complex topics logically, etc.)
o4-mini-high
Similar to o3 but better at certain tasks. Haven’t used it enough to give my full impression. I glossed over the test scores above and it seems o3 is better than o4-mini at things I care most about.
Marketed as “great at coding and visual reasoning.”
That said, I stumped o4-mini-high on every image/artist identification I threw at it. Mostly used some complex types of cartoons (e.g. throwbacks from The New Yorker). It was guessing Wojak and Soyjak memes which was somewhat comical but to be fair there was some resemblance. It was confident that it was correct, but it was far off.
o3-mini-high: Never liked this model much. Felt like a shitty in-between from GPT-4o to o1-pro. It was good at spitting out long answers, never too impressive… seemed more spammy than anything. Nothing compared to standard o3. Feels completely different. I liked o1 & o1-preview more than o3-mini-high (even if o3-mini-high was better)… output just felt spammy.
GPT-4.5: A slower version of GPT-4o that is less repetitive (less likely to use predictable phrasings like “delved” and other shit). It’s also a tad smarter on certain topics (but GPT-4o has beaten it in certain head-to-head tests I ran). Would use this over 4o if it was as fast. It has a better personality as well.
GPT-4o: Fast AF. Good image generation (a bit slow). Good at tracking conversations. A very strong all-around model. I still use it regularly for refinements, creating charts, etc. Only downside is it’s just not quite as good at certain tasks as other models. Very useful in the right scenarios. (I use it if I have content from like o3 or o1-pro and need it written in a more aesthetic format or table.) The reasoning models don’t have the formatting aesthetics as optimized as 4o.
What about GPT-4.1? Allegedly better than GPT-4.5. Some sort of an upgrade. The numerics may confuse you… 4.1 superior than 4.5? I thought more was better. Well… not the case here. Just keep track of it. I can use it… just don’t feel any urge to use it when I have o3. Maybe I’ll get around to trying it. (It’s not as good as Gemini-2.5.) Okay so I just asked GPT-4.1 how it compares to 4.5 and 4o — here’s its answer:
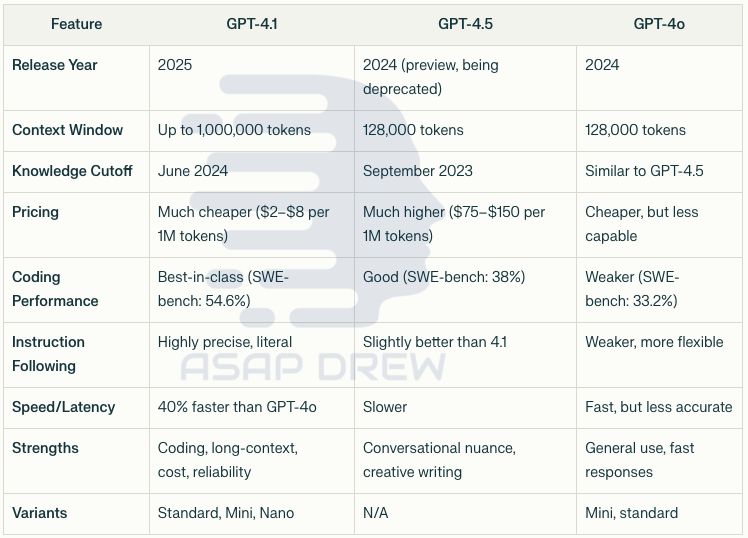
Note: I always laugh at people who rip on OpenAI to change the names of their models. I LIKE THESE NAMES even if not socially acceptable. Gives you the chance to parse out the nuances between each. I guess they could do AGI-1, AGI-2, AGI-3 like I recommended once they achieve this. AGI increments.
What about Gemini 2.5, Grok 3, Perplexity?
I didn’t feel like writing up a full post on Gemini 2.5 because I still favor ChatGPT.
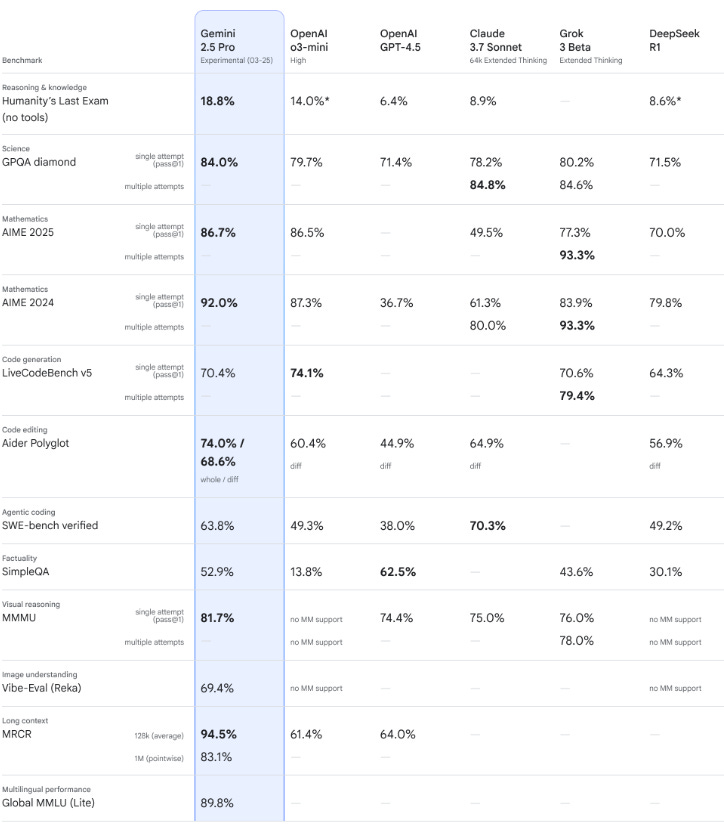
That said, I have used Gemini 2.5 quite extensively over the past 7-10 days and am highly impressed. It’s fast and a clear upgrade from 2.0. It was the best fast model prior to o3’s release objectively — and in my experience.
On several occasions it gave me an answers immediately that others could not find with ChatGPT. These weren’t urgent/complex answers, but these were questions with an objective specific answer and it spat them out immediately.
I still hate on Gemini because it refuses to answer and/or engage with certain topics (anything remotely sensitive e.g. politics). Google is competing… but this is what I expected. Logan Kilpatrick et al. are crushing it.
I should give Google credit for having “Deep Research” before OpenAI, but Google’s Deep Research sucked! I tested it many times and you have to ask follow up questions (it’s not a comprehensive report). It also uses more “sources” but a lot more of those are slop/junk/spam type sources… no real quality filters.
Additionally, several times I tried “Deep Research” with Gemini it just crashed out. That was the final straw for me and I canceled my subscription. But yeah I hope they’ve improved their “Deep Research” product… it should be better than everyone… but was pathetic last I used it with 2.0.
Alright… the Gemini Deep Research hating is out of my system… I’ll reiterate that Gemini 2.5 is fire.
Is it as good as o3? No. Is it better than most other models? Yeah. Is it worth using? Yeah. Just give it a shot… it’s a really likable model.
Gemini-2.5: The first Google model that I’m HIGHLY impressed with. Not that their other models sucked, but they always played second fiddle (in my experience) to OpenAI’s ChatGPT. Gemini has always been a really strong image generator, but it’s not as good as ChatGPT’s (in terms of specifics).
Grok 3: Very helpful for an analysis of posts on X. Often highly accurate even without “thinking” now. They’ve improved it quite a bit since initial release. Deep Research on Grok is not nearly as good as Deep Research with ChatGPT… but it’s not bad either. It holds its own. Has gotten better over time. Best feature of Grok is that it does things all other AIs refuse (lower censorship). I still have high hopes for Grok’s future knowing how competitive Elon is.
Perplexity: Combined with Gemini-2.5 has been my go-to if I need search. Now that o3 is out I now just use o3. It’s maybe not quite as fast as Perplexity with Gemini 2.5, but it typically gets me a more robust/elite answer. This got me wondering if Perplexity will eventually go defunct with new AI upgrades that improve on their search capabilities. o3 can now search very well.
Note: I haven’t been using Claude anymore. (Claude sucks?) I do occasionally use Claude 3.7 Sonnet Thinking… but was rejected for some prompt and just said well fuck it. I just assume it’s pretty solid (has always been good) but neutered. It’s no longer the best at anything either. What about Mistral and others? No need. I don’t even bother with DeepSeek anymore. DeepSeek could take the lead soon especially if they embrace visual identification and rapid output of complex images/infographics… but I view DeepSeek as a Chinese brand knockoff of ChatGPT trying to play catchup. Yes they have some insanely high IQ people that are innovating in architectures and cost, but I’m not expecting them to leapfrog anyone. Their “best” model was never the best even when it dropped. I like the model too, but it was overhyped to an insane level.
What I like about each of the AI models (April 2025)…
Subject to change. This is how I’m using the models in April 2025.
ChatGPT: Best interface by far. Custom image generation. Graphics. Conversations. o3 does it all. o4-mini-high does very well with image gen. (o3 = all-around daily driver — does everything. search game on point; o4-mini-high = graphic output; 4o = rapid fire clean up & formatting; o1-pro: organizing massive amounts of info. without internet). o3-mini & o3-mini-high = I’m a hater.
Gemini-2.5: Conversations. Image gen. Insights.
Grok 3: X analysis. Checking ChatGPT’s output for errors.
Perplexity: Occasional searches. Using with Gemini-2.5 (until something dethrones it for rapid-fire search). 4.1 would probably be decent too.
Claude 3.7 Sonnet: Nothing. I don’t use it anymore. No need.
DeepSeek: Nothing. Last time tried image analysis facial recognition and art recognition and it’s trash.
Other Chinese models: I don’t bother unless they are clearly #1 (by a decent margin) on benchmarking.
Mistral: Tried it but irrelevant.
o3 has made me feel dumb at times…
Not gonna tell you my query. The output was akin to someone speaking to me in an alien language. I did NOT understand half of what it wrote in one response — was beyond my domain of expertise and/or beyond my IQ threshold.
Does it do this for every topic? No. In some cases I’ve had to correct it. But on science topics it does exceptionally well. I may have to dig into its methodological analyses and weights when doing a “big picture” takeaway.
I have disagreed with it and it is quite prolific at dealing with pushback. Sometimes it assumes it’s correct — when there’s an objective analysis of facts but interpretation is somewhat open/confidence levels/odds (rather than definitive).
At one point it wanted to create a mega database and pull a zillion APIs and become an expert day trader. It engineered an entire protocol from start to finish. I’m not sure how much I’d trust it to properly execute, as it has made small errors etc. Perhaps the full o4 will be day-trader ready.
Nonetheless, it claimed it could generate 35% annual returns with zero risk. I won’t give away its methods, but after reviewing them the estimated returns seem plausible. OpenAI should seed an o3 agent or o4 with some resources and see how well it does as a day-trader with minimal oversight.
You can feel dumb too! Just use o3 for some complex field in which you have minimal preexisting knowledge and ask something complex.
I would suggest that if you don’t feel dumb/stupid at times while using o3, you aren’t using o3 to its fullest extent; you’re leaving artificial cognition on the table.
What if everyone in the world had o3 & o4? (Queries & outputs constrained by each specific user)
Would be cool, but most people would NOT be able to effectively leverage these models to their fullest extent. Most people can barely leverage o1/o3-mini well.
If you think about gradients of intelligence/cognition, people are capped by their own capabilities (myself included). So if you think of someone really lacking in cognition, they might ask some really basic stuff — whereas certain brainlets will have o3 printing innovative ideas and solutions.
The really basic stuff is best served by GPT-4o — o3 may confuse many. Remember if you’re average IQ of ~100 — you are smarter than much of the world (~89 IQ)!
Most people are limited by their own prompting and comprehension of the AIs output. You could give everyone some elite level AI (e.g. o5, o6, o7, o1000-pro) and they literally would not be able to: (1) prompt shit that’s worth a damn OR (2) understand the outputs in a way that would allow them to capitalize.
What’s coming down the pipeline? Perhaps fleets of agents operated initially by high IQs but then anyone because the AI can just execute. You just tell it what you want done and it helps refine the request and delivers.
In other words, the AI will be able to sense the user’s IQ level, goals, etc. and execute in high IQ ways while communicating to lower IQ users. It achieves their goals, explains what’s going on in a dumbed down way, etc. — meaning maybe everyone can still get what they want? Idk.
Will everything on the internet eventually be accessed via an AI OS/ChatGPT interface? The internet seems to be disincentivizing unique content from non big biz. Everything reads like a LinkedIn profile.
Internet is being siloed into: (1) authentic/unique content with AI augmentation; (2) slop copies; (3) social media (some of which is just AI slop and bots).
Word is that OpenAI is working on a social network. My reaction? Extremely smart — but will depend on the specifics and execution. This is something I thought OpenAI should’ve done years ago (perhaps they were working on it.)