


OpenAI's New o3 & o3-mini Models
OpenAI is going "all-gas-no-brakes" with chain-of-thought (CoT) models - announcing the release of o3 (outperforming o1)

OpenAI was first to introduce “Chain of Thought (CoT) AI models to the masses which demonstrated significantly upgraded reasoning capabilities via a programmed multi-step sequence of “thinking.”
Initial CoT models dropped in September 2024: “o1-mini” and “o1-preview” (o1 was codenamed “Strawberry”)… just 3 months later we get the full o1 and a beefed up version called o1-pro (it thinks for longer than o1 and achieves higher accuracy).
In my experience, o1-pro is currently (Dec 2024) the best AI model for advanced reasoning/logic.
o1-pro is in the big leagues batting cleanup… Google’s Gemini, Claude’s Anthropic, and DeepSeek are playing Triple A ball batting 7-9.
Hordes of prognosticating nerds on X/Twitter have been speculating for years that LLMs are “hitting a wall” or “close to hitting a wall” because they hadn’t gotten an upgrade in months, but those calling for the imminent wall can shut up for a while.
Everyone sees what OpenAI has achieved with CoT architectures and competitors are scrambling to play catchup (i.e. swagger jack OpenAI’s CoT architecture to stay in the AI arms race).
Meanwhile, OpenAI is going all-gas-no-brakes (“0-to-100-real-quick”) with CoT advancement and announced the preliminary debut its new CoT model dubbed “o3” on their final day of “Shipmas” 2024.
What is Chain-of-Thought (CoT)?

Most language models (LLMs) produce answers in a single pass, never exposing the intermediate steps of reasoning.
By contrast, Chain-of-Thought allows the AI to generate a series of “reasoning tokens” or sub-steps.
This explicit multi-step reasoning:
Systematically breaks down complex problems (like competition math or multi-file code generation).
Reduces logical shortcuts by tracking partial progress and detecting inconsistencies.
Supports error-correction since intermediate steps can be reevaluated.
CoT Features:
Intermediate Reasoning Layer: Rather than jump from question to final answer, the model uses an internal hidden “thinking layer.”
Reinforcement Learning (RL) on Each Step: Models like o1 and o3 are rewarded for correct reasoning sequences, not just final correct answers.
Self-Consistency & Majority Voting: Generating multiple possible solutions and picking the most common or verified one can dramatically raise accuracy on tasks like math and code.
The Evolution: o1 → o1-pro → o3
OpenAI’s o1 (released in preview and “mini” forms) debuted this multi-step approach.
Soon after, o1-pro arrived, offering a “longer thinking duration” for higher accuracy, albeit at higher cost and latency.
Then, just 3 months later…
o3: A Rapid, Unexpected Leap
Surpassed many state-of-the-art models on advanced benchmarks (math, coding, abstract puzzles).
Introduced a mini variant, o3-mini, with variable “low/medium/high” reasoning modes to balance cost vs. performance.
Notably skipped naming the model “o2” due to potential trademark conflicts with the British telecom company O2.
Performance Highlights
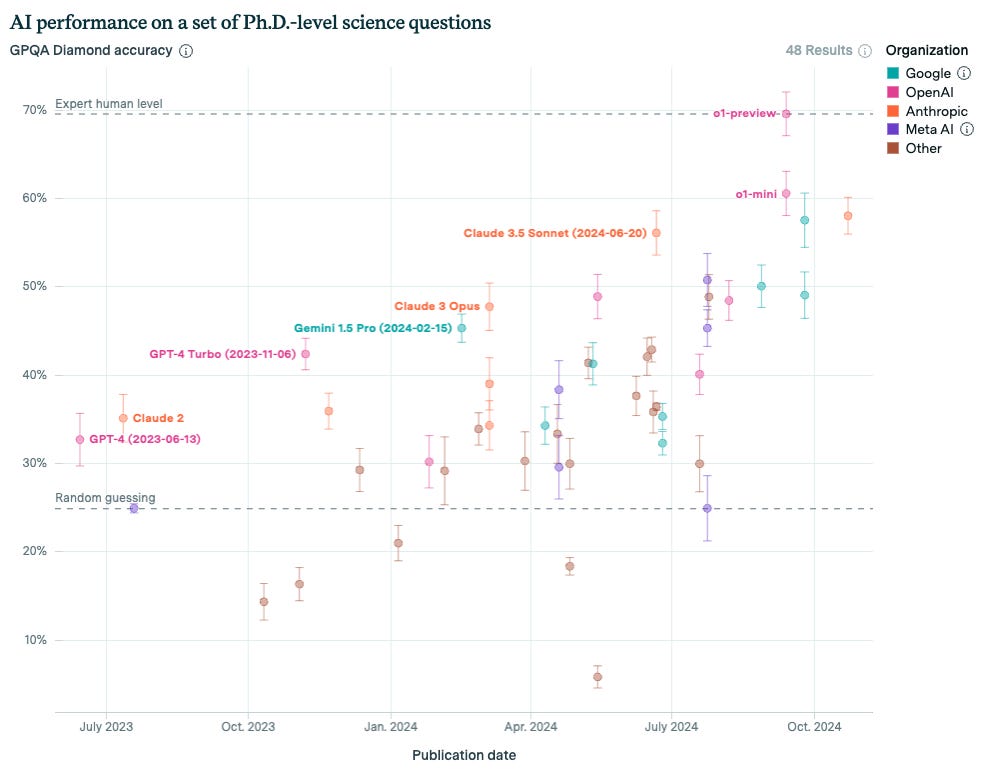
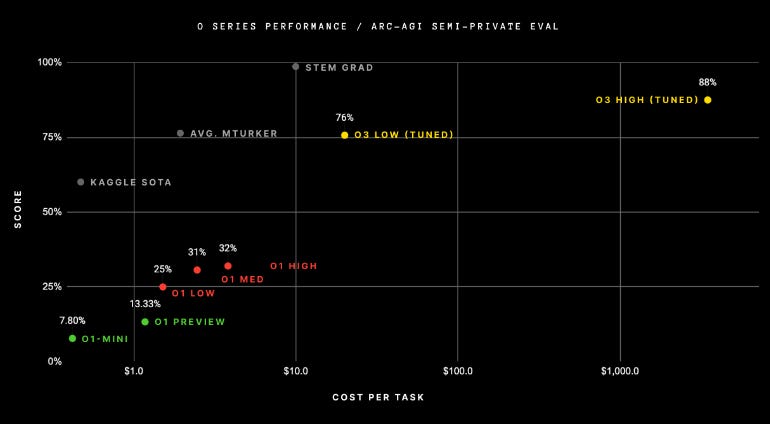
ARC-AGI: Jumped from ~5% (previous top-tier LLMs) to ~87.5% with “high-compute” mode, surpassing even many human benchmarks.
FrontierMath: Scored 25%+ where prior best solutions lingered below ~2%.
Competitive Coding: ELO of 2727 on Codeforces in top-end mode, placing it among the top 200 coders worldwide.
GPQA Diamond (PhD-level science): ~87.7% accuracy, whereas human PhDs average around 70%.
o3 Tested on ARC-AGI
OpenAI’s newest o3 system was tested on the ARC-AGI-1 datasets under two compute settings. (Read the full testing details from Chollet)
High-Efficiency (6 samples, ~33M tokens)
Low-Efficiency (1024 samples, ~5.7–9.5B tokens, roughly 172× the compute)
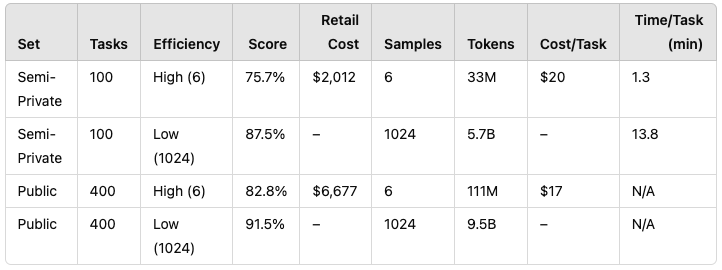
High-Efficiency: Runs cost $17–$20 per task, letting o3 hit ~75.7% (Semi-Private) and ~82.8% (Public). This qualifies for 1st place in ARC-AGI-Pub under a $10k compute limit.
Low-Efficiency: 1024 samples soared to ~87.5–91.5%, but cost is extreme—hundreds or thousands of dollars per query.
This reveals two things:
o3 adapts to unseen tasks far better than older GPT-4 styles; scaling test-time compute does yield big gains.
Cost is still higher than hiring a human ($5–$6) for ARC tasks. But that gap may shrink quickly as hardware and software optimizations improve.
ARC-AGI-2 & the 2025 ARC Prize
The ARC Prize Foundation is raising the bar with ARC-AGI-2 in 2025.
Early signs suggest it might drop o3’s performance below 30%—again emphasizing that passing ARC-AGI-1 doesn’t mean “AGI.”
The new benchmark will continue testing the model’s ability to tackle truly novel tasks that remain straightforward for humans.
SWE-Bench Verified (71.7% for o3)
On SWE-bench Verified - an agent-focused coding benchmark derived from real-world GitHub issues - o3 scores an impressive 71.7% accuracy.
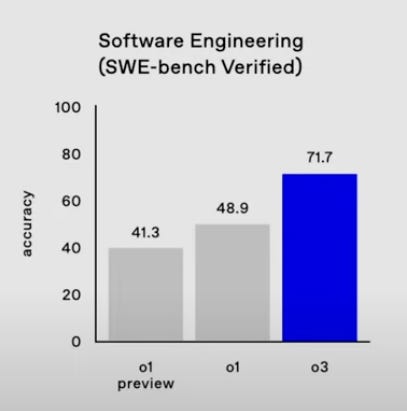
In comparison, o1 previously scored 48.9%, and o1-preview just 41.3%.
This 20%+ jump is unprecedented and signals a “step function” improvement in coding tasks that require multi-step logic, debugging, and domain reasoning.
Codeforces ELO vs. Cost
OpenAI employees shared a chart mapping Codeforces ELO performance against estimated cost.
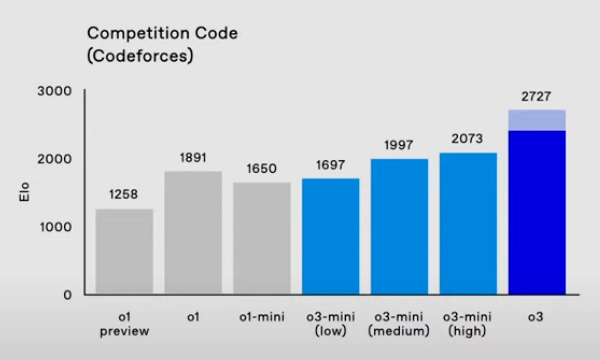
Full o3 tops out near the 2400 ELO mark - putting it among the best competitive programmers worldwide - at a hefty compute cost.
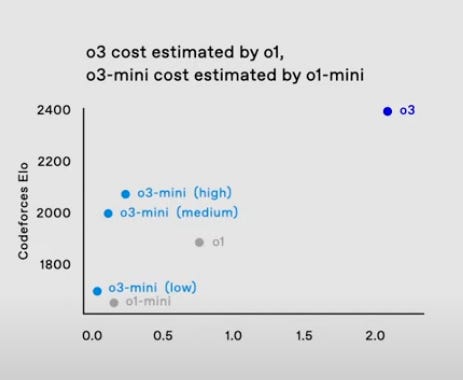
Meanwhile, the o3-mini variants (Low/Medium/High) deliver ELOs ranging from ~1900 to ~2100 at varying price points:
o3-mini (Low): ~1900 ELO at ~0.3–0.5x cost
o3-mini (Medium): ~2000 ELO at ~1.0x cost
o3-mini (High): ~2100 ELO at ~1.5–2.0x cost
This visual demonstrates the new “frontier” in coding performance: spending more tokens and time scales code-writing skill higher.
Notably, “o3-mini (High)” already outperforms older full-sized models like o1.
Test-Time Compute: The Core of Scalability

One of the biggest breakthroughs in o1 and o3 is scalability through inference-time compute.
Instead of training bigger base models, scale the inference process by allowing the AI to generate multiple parallel solutions (samples) and vote on the best.
How It Works:
Repeated Sampling: The AI generates multiple candidate solutions for the same prompt.
Majority Voting / Self-Consistency: The answers are compared or validated (via an internal verifier model), and the consensus is chosen.
Tradeoff: Each additional sample significantly increases token usage (and thus cost) and also adds latency.
Gains in Accuracy vs. Cost
Minimal sampling (6–8 passes) can already beat standard single-pass LLMs.
Going all-out at 1024 samples often breaks new benchmarks but can balloon inference costs to $500–$1,000+ per query.
Latency (Time per Response) & Cost Efficiency
Multi-step reasoning might take 5 seconds or even minutes per answer, depending on how many samples and how large the chain-of-thought is.
For ARC-AGI specifically, “high-efficiency” runs (~6 samples) cost $20 per task vs. $5 for a human—but that gap is expected to narrow as GPU tech advances.
Hardware Upgrades: Next-gen GPUs like Blackwell (likely 2025–2026) could slash token costs.
Software Optimizations: Smarter partial verification, curated sampling, or adaptive compute to dial up reasoning depth only when necessary.
Remain Expensive at the High End: Even if cost halves, going from 6-sample to 1024-sample is a 170× jump—so “maximum synergy” remains pricey.
Latency in o3 Models
A recent OpenAI chart shows time-to-first-token (p50) across several models. GPT-4o remains the fastest with a median ~0.5s, while o1-mini clocks in around 3.8s and o1 at ~8.9s.
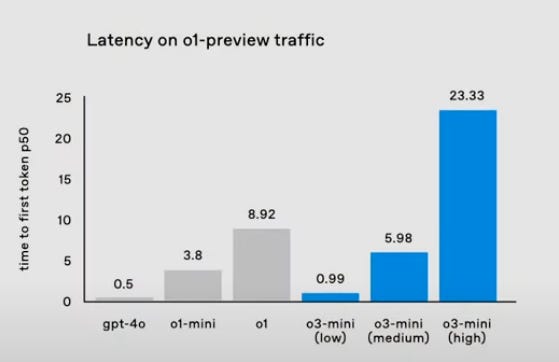
Notably, the new o3-mini variants offer three “thinking depth” modes:
o3-mini (Low): ~0.99s
o3-mini (Medium): ~5.98s
o3-mini (High): ~23.33s
In other words, o3-mini (Low) rivals GPT-4o’s near-instant response times while retaining decent chain-of-thought capabilities.
Choosing medium or high modes boosts accuracy in math/coding tasks but significantly raises latency, reflecting the new “pay more compute for more reasoning” paradigm.
o1 & o3: Ideal Use Cases vs. “Overkill”
o1 and o3 are transformative for complex logic, but casual or everyday Q&A users may see limited benefit (or may not notice at all).
Complex Coding: Full code interpreters, multi-file debugging, HPC scripts.
Advanced Math/Science: Frontier-level problem sets, scientific theorem checks, R&D analyses.
Financial & Quant Trading: Intricate risk modeling, Monte Carlo simulations, chain-of-thought on large portfolios.
Legal & Policy: Multi-argument briefs, advanced compliance checks, reasoning over large case precedents.
Casual queries don’t need advanced reasoning.
Most will complain that advanced CoT models don’t seem any better than standard ChatGPT…

I’m of the opinion that you could give most people in the U.S./world access to the most advanced o3 model and a majority would be unable to detect/perceive that it’s significantly better than standard ChatGPT.
Why? A combination of things: (1) Type of queries your avg. Joe will ask AND (2) perceptual constraints (does a 100 IQ person really know what a 130 IQ answer is?).
At a certain point within the next 5-10 years there may be a 300 IQ model but it might be that even the smartest humans (e.g. 150-200 IQ) are unable to fully leverage/utilize it due to their own limitations (perceptual, IQ, etc.).
Currently only those who need advanced reasoning/logic for specific types of work (these tend to be above-avg IQs) effectively prompt the latest CoT models to notice massive differences (vs. non CoT models)… and they’ll likely be highly impressed.
Your avg. person prompting things like: “Why won’t my dog stop barking?” or “Why does flu spread in the winter?” or “How is Elon Musk so productive?” or “What is the best chocolate chip cookie recipe?” – won’t benefit much from the CoT models (maybe marginally).
Some might even laugh at how the most advanced models are so expensive and/or think that they’re worse than standard ChatGPT (without CoT).
Need proof? Just browse X/Twitter and/or read some recent news articles and/or forums (e.g. Reddit) about o1 and o1-pro… you’ll see that many aren’t impressed (this is comical and mostly reflects how the person is using it and/or their ability to judge).
On the other hand, a software engineer who needs database errors corrected, a scientist working on curing cancer, a trader running mathematical frameworks for crypto options, etc. will generally notice a big difference between standard ChatGPT and CoT models.
Getting the most out of advanced CoT models requires above average intelligence and specific use cases… even with equal access, some will leverage advanced models more effectively for ROIT/ROIC and others won’t get much additional benefit beyond standard models.
Workforce Implications & the Next “o” Models
The rapid iteration from o1 to o3 suggests o4, o5, etc. may follow sooner than expected, amplifying concerns about job displacement.
Growing Capabilities, Growing Pressure
Coding: Future o4 or o5 might handle entire software lifecycles. A single engineer using a top-end CoT model could potentially replace entire teams.
Office/Analytical Roles: Finance analysts, data scientists, or operational roles may be reduced if advanced chain-of-thought is cheap enough to run for every question.
STEM Research: If the model can solve or hypothesize solutions for novel experiments, some tasks of scientists or research assistants might become partially automated.
Rate of Improvement vs. Bottlenecks
Hardware Bottlenecks: HPC resources are the biggest gating factor. Even if the software is brilliant, it needs hundreds of thousands of high-end GPUs to handle large-scale demand.
Data Bottlenecks: Building advanced reward models (especially for new domains) still requires high-quality training data.
Cost Bottlenecks: High “search” modes remain expensive, limiting usage to well-funded enterprises initially.
Societal & Workforce Shifts
Short-Term: Blended “AI + human” workflows, with high-end specialists using CoT models to boost efficiency.
Medium-Term: Displacement in coding, data analysis, or specialized tasks as costs drop and more companies adopt.
Long-Term: If future o-models converge on “AGI-level” reasoning for all knowledge tasks, entire industries might be restructured around AI-first workflows.
Do OpenAI’s CoT models prove that software is more important than hardware?

No – this is a common take, but it’s wrong. AI companies are in a hardware war.
Hardware remains the single most important variable in the AI arms race.
Compute: Large CoT inferences can saturate GPU clusters.
Parallelism: A 500k-GPU supercluster can run repeated passes far more cheaply and quickly than a 20k-GPU setup.
Outcome: Hyperscalers with bigger HPC budgets—Microsoft, Meta, XAI, Alphabet—can out-scale rivals on accuracy and cost if they replicate or improve upon OpenAI’s chain-of-thought designs.
It’s not that software engineering and innovation is easy, it’s because the big dawgs (Alphabet, Meta, Microsoft, XAI, etc.) have enough elite engineering talent that there’s limited-to-zero software engineering moat.
A company with good-enough engineers will win out long-term over a company with elite engineers if the good-enough engineers have a 500k Blackwell GPU supercluster and the other company is stuck with 20k H100 non-clustered GPUs.
Why? The 500k Blackwell GPU supercluster can train AI models faster and generate higher output efficiency (power costs, speed, etc.) than the non-clustered… giving this team a major advantage.
As Elon said, think about hardware like racecars, if you’re racing and you have Car A with 5k horsepower and Car B with 2k horsepower – the 5k horsepower provides an advantage (assuming proper efficient integration).
Obviously other things matter, but all-else being equal, the horsepower will have an unfair advantage vs. one with less than half.
Software engineers are not only poachable, but even when they aren’t, competing companies can kind of guess the type of architectures that went into a certain successful model… so when OpenAI rolls out o1/o3/etc. – Alphabet/Google, XAI, Microsoft, Meta, et al. replicate it ASAP.
They might even replicate and enhance and when coupled with their hardware firepower, they make these models more efficient for both commercial and consumer use – some even may find ways to improve/scale faster… so OpenAI needs to keep up the acceleration or risk losing their competitive edge.
What about data? This can be stolen via hacks, leaks, bribes, etc. If you think this is impossible, just look at what the Chinese have accomplished.
So while programming innovation is important, all companies have good programmers so the moat generally ends up being days, weeks, or months in this AGI race… companies deploying the most/best hardware setups will win.
Rate of Improvement vs. Future Outlook (o4 & o5 Models)
o3 emerged roughly 3 months after the full o1.
Many experts expect the next wave (o4, o5) within 6–12 months, provided hardware builds keep pace.
More Domains: Potential expansions into advanced robotics, 3D design, or real-time analytics.
Growing “Reasoning Depth”: 2048 or even 4096 parallel samples? Possibly feasible with next-gen HPC.
Societal Adjustments: With each cost reduction, job disruption accelerates—balanced by the new roles and new markets AI may create.
Appendix: o3 Inference Modes
o3-mini (Low)
Latency: ~1–2 seconds
Cost: ~1× baseline
Use Case: Lightweight everyday queries, short coding tasks, modest precision
o3-mini (Medium)
Latency: ~2–5 seconds
Cost: ~2–3× baseline
Use Case: Complex but not extreme coding/math, daily enterprise tasks
o3-mini (High)
Latency: ~5–15 seconds
Cost: ~5–10× baseline
Use Case: Approaches pro-level reasoning for moderately difficult questions
Full o3 (High Compute)
Latency: 30 seconds to several minutes
Cost: Potentially $100–$1000+ per query
Use Case: Cracking toughest problems (ARC-AGI, high-tier math), critical production workflows needing near-flawless accuracy
OpenAI Staff Reacts to o3 Models
Jason Wei (@_jasonwei) notes: “o3 is very performant. More importantly, the jump from o1 to o3 in just 3 months shows how fast RL on chain-of-thought will evolve—much faster than the 1–2 year cycle of old pretraining paradigms.”
Sam Altman (@sama) highlights that “o3-mini can outperform o1 at a massive cost reduction,” though “marginally more performance for exponentially more money” will be a weird new economic reality.
Hongyu Ren (@ren_hongyu) adds that o3-mini “maximally compresses the intelligence from big-brother models,” letting users scale up or down the chain-of-thought to suit cost/latency needs.
OpenAI’s o3 Models (Recap)
OpenAI’s chain-of-thought models (o1, o1-pro, and now o3) show us what’s possible when you blend large language modeling with explicit, multi-step reasoning.
The results are unprecedented in coding, math, and abstract logic, albeit at a time and cost tradeoff that can be staggering at high settings.
Yet the trade-offs—long latencies, high per-query costs, and the looming specter of workforce displacement—underscore the complexities of deploying these advanced Chain-of-Thought systems at scale.
With hardware (GPU superclusters) remaining a prime bottleneck, the next steps (o4, o5) may hinge as much on HPC availability as on software ingenuity.
For casual users, simpler LLMs or small-scale CoT modes suffice, but for specialists in R&D, finance, law, and software engineering, o3 is a glimpse of how AI-driven reasoning can outperform even highly skilled humans on niche tasks—potentially rewriting the rulebook for entire industries.
End Notes: We have entered an era where AI not only “answers” but “thinks”—and that thinking can be dialed up or down based on how much time, compute, and money you’re willing to spend for the best possible solution.
Chain-of-Thought is the new frontier: multi-step internal reasoning significantly boosts logic and advanced problem-solving.
o3’s Capabilities: Crushed existing benchmarks (ARC-AGI, FrontierMath, competition coding) but remains expensive to fully leverage.
Time/Cost Scaling: More “thinking steps” → higher accuracy but exponential jumps in GPU usage and latency.
Future “o” Models (o4, o5…) could expand CoT to a superhuman level across more complex tasks, driving down costs over time, and potentially shaking up the workforce even more.
Overkill for Casual Use: Not everyone needs or wants to pay for a 30-second $500 query about trivial matters. Expect specialized use among power users—developers, quants, scientists.