


Grok 3 Unleashed: xAI, Elon Musk, & the 200k GPU "Colossus" Supercluster (Feb 2025)
Grok 3 from Elon Musk & xAI is... better than expected, highly competitive, not yet the best... but it will get better. Other labs feel the heat.

Grok 3 dropped on February 18, 2025… and xAI did very good work (i.e. “cooked”). I am impressed that xAI was able to “out-grind” most other AI labs and basically catch-up with OpenAI’s new o3 models (o3-mini-high) in short-order (they aren’t quite there yet, but are now a legit contender for the throne). (I did expect this cuz they have Elon, but wasn’t sure how good Grok 3 would be.)
It helps when you have the genius that is Elon Musk bankrolling a GPU supercluster, recruiting & poaching elite AI talent, and strategizing (doing things nobody thought possible).
Elon’s mentality seems to be: outgun the opps with hardware (this is a “hardware war”)… who has the best/latest hardware and hardware setup/optimization. Part of the reason I’m rooting for xAI is because I have a similar line of thinking to Elon here (GPUs, more GPUs, better GPUs, bigger GPU clusters, 1 gazillion GPUs).

If everyone has maximum efficiency and roughly equal engineering talent, the only potential edge is having more/better hardware and/or a better/optimized hardware setup. If you have a GPU supercluster of 1 trillion GPUs and other labs only have 1 billion — and you’re able to actually use all trillion effectively, you leave other labs in the dust. (Obviously if you can’t use them effectively this is irrelevant, but Elon is betting that they can figure it out.)
Elon came up with the idea to create a massive “supercluster” of 100K GPUs when engineers from other AI labs scoffed at the idea and claimed impossible or that it would take “years”… everyone said Elon was delusional.
What happened? Elon and the xAI crew assembled the 100K GPU supercluster “Colossus” in ~122 days (Jensen Huang called this a “superhuman feat”). This was the first genius move that only Elon was able to pull off… competitors then scrambled/panicked to copy this strategy.
Thereafter, Elon and the xAI crew upgraded the 100K GPU supercluster to a 200K GPU supercluster over an additional ~152 days (about 5 months)… another insane feat. Elon now plans to get the cluster up to 1 million NVIDIA GPUs as rapidly as possible. (But akshually DeepSeek killed NVIDIA though so this can’t be true, right?… lol).
Rate of Advancement: Grok 1 → Grok 2 → Grok 3
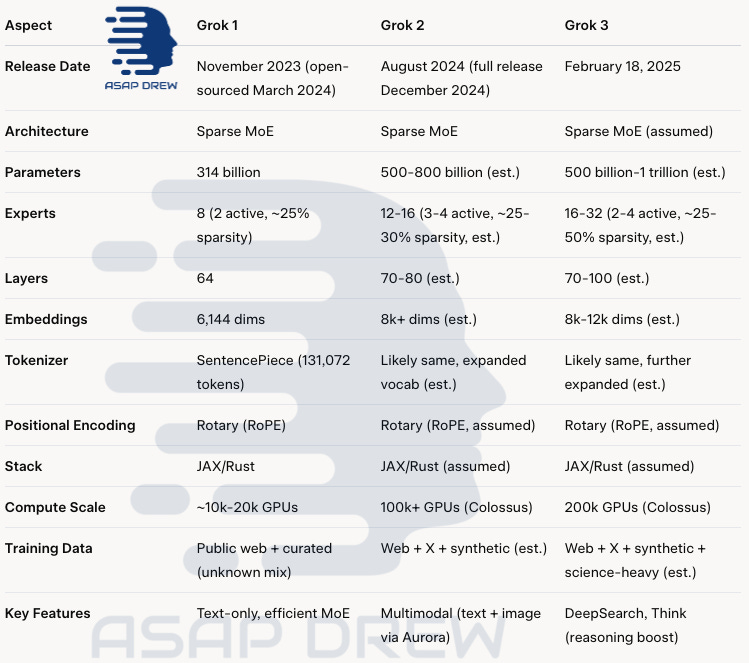
xAI founded (Mar 31, 2023): According to biz registration records. Company starts working on a model. Around ~158 days of prep time (5.2 months) for setup, hiring, and planning (March 31 to Sept 4) before starting Grok 1 training.
Grok 1: Released November 4, 2023. This took around 7 months (218 days) since the company was publicly announced. Training of Grok 1 took ~2 months (60 days) from Sept 4 to Nov 4. This was a sparse MoE design with 314B parameters, 8 experts, 2 experts/token, 64 transformer layers.
Grok 2: Announced and released August 14, 2024. It took ~9.5 months from Grok 1 to Grok 2. Speculation: Thought to be 500-800B parameters, 12-16 experts, multimodal via Aurora, maybe 3-4 active/token, etc.
Grok 3: Released Feb 18, 2025. This comes ~6.1 months (187 days) after Grok 2 and is a massive upgrade. Speculation: Thought to be a sparse MoE (16-32 experts, 2-4 active, ~25-50% sparsity) with more layers (70-100), wider embeddings (8-12k dims), with a lot of synthetic data and smart router or CoT-inspired pretraining and possibly multimodal hints.
The rate of progress here is insane. I don’t care if you have Elon’s bankroll or poached AI engineers that a grinding… I don’t think any other lab could’ve pulled this off or gained as quickly as xAI… they are working like Alaskan sled dogs.
Example: Meta has a massive bankroll yet is nowhere near xAI’s Grok with their “Llama.”
A few things helped xAI catch cutting-edge “SOTA” models (2025):
Massive GPU supercluster: This was Elon’s idea. Nobody thought possible. 100k at first, then 200k. Many people saying this was dumb (still gets criticized)… yet many other labs copied and/or felt threatened.
Poaching talent: Elon has been recruiting/poaching elite AI talent from all labs… this is a smart move.
Other labs paving the way: Other labs had to figure out what works best for training. They scaled massive pretraining models then hit a wall (xAI benefitted from them wasting time/$ with this wall). Then other labs had to think of “what’s next?” after giant pretraining methods. OpenAI realized test-time compute and inference scaling was the next paradigm (everyone hopped on this bandwagon). For xAI the catchup path became clear (hence their more efficient progress).
Hardware spend/cost: Elon went brrr on the GPU spend. Also helps that other labs had to spend a ton of money each year on GPUs (without ROI) and xAI stepped in at this specific time (efficient wayt o
Data from X: Many AI labs wish they had access to the massive real-time data repository from X.com (only xAI has this).
A disadvantage for xAI is that they started late and most LLM users are somewhat locked-in to ChatGPT… it’s more difficult to get people to switch to xAI from the familiar ChatGPT.
I think this is why the xAI interface is similar to ChatGPT (DeepSeek interface similar as well)… easier for people to switch if everything looks similar.
My initial impression of Grok 3? The more I use it, the more I like it. Do I think it’s the absolute best model in Feb 2025? No. However, for certain queries I like the answers I get from Grok 3 more than ChatGPT… for the most advanced logic/analytical queries, I think ChatGPT remains a bit better.
I really like the fact that Grok 3 can reference/analyze real-time posts from X/Twitter (this is a unique offering that other AI labs can’t compete with). Since X tends to post the latest news before most other sources, it should have a real-time data advantage.
Where do we go from here? The inference scaling paradigm is well-known. xAI isn’t yet going down the custom chips route so is going all in on Jensen and NVIDIA (“there is currently nothing better than NVIDIA hardware for AI”).
Other AI labs want to “decrease reliance on NVIDIA” and Elon is saying… you know what… maybe I’ll just go all-in on NVIDIA and see how things shake out. This puts massive pressure on other labs to really deliver with their custom chips.
Basically if other AI labs waste too much time/energy with “custom chips” (development, setup, integration, etc.) and/or the custom chips don’t deliver as well as they’d hoped — xAI pulls ahead.
Elon & xAI are betting that NVIDIA chips keep getting so much better that these “custom chips” may not even be a smart move.
This creates a “prisoner’s dilemma” for other AI labs… do we try to stay competitive with Elon and xAI by maxing our NVIDIA spend or do we go custom or what? The other possible advantage now that Elon may be committed to going all in on NVIDIA is Jensen Huang may favor him in terms of who gets chips first.
A company like xAI buying a massive bulk GPU order each year and not trying to “wean” off of NVIDIA is probably in better standing with NVIDIA (Jensen Huang) than say OpenAI, Anthropic, Gemini, etc. trying to decrease reliance on NVIDIA.
The added layer to this prisoner’s dilemma is a relationship layer. Jensen should logically prioritize customers that value NVIDIA highest (biggest orders & fully committed to NVIDIA). This would be xAI.
Not saying this will necessarily happen, but it could give Elon & xAI a big advantage if first GPUs go to xAI and/or xAI is prioritized if there’s a shortage… Remember these tend to sell out rapidly. Why? They’re the only major competitive edge (these labs all have smart people).
Read: NVIDIA GPUs vs. Custom Chips: Who Wins the War? (2025-2030)
Read: Can NVIDIA Maintain an Edge in an Inference-First Era?
Grok 3 (xAI): February 2025 Debut, Hype, & HPC Breakthrough

xAI unveiled Grok 3 in February 2025, declaring it the “smartest AI on Earth” in certain tasks and showcasing its stealth success on LMArena (codename “Chocolate”).
The reveal discussed xAI’s Memphis data center—nicknamed “Colossus”—built in 122 days to host ~100k Nvidia H100 GPUs initially, later doubled to ~200k.
Rapid Data Center Feat
Initially, the site had only 15 MW power capacity, far below the 120 MW+ needed.
xAI overcame this gap with mobile generators, advanced liquid cooling, and Tesla Megapacks buffering volatile GPU power surges.
Rival engineers labeled the timeline “impossible,” but Elon Musk’s “spend whatever it takes” approach proved otherwise. Nvidia’s CEO, Jensen Huang, called it “superhuman.”
“Grok” & xAI’s Cosmic Mission
Name Origin: “Grok,” from Robert Heinlein’s Stranger in a Strange Land, means to fully and profoundly understand—capturing xAI’s ambition for deep comprehension.
Universal Curiosity: xAI asserts a “maximally truth-seeking AI” is vital for tackling fundamental mysteries: cosmic origins, alien life, potential ends of the universe. They reject extensive guardrails, believing unfiltered HPC + chain-of-thought can yield breakthroughs.
Beta Release & Daily Updates: Grok 3 is labeled beta, with partial re-training or fine-tuning occurring almost daily. Observers caution that performance measured on Day 1 might not reflect the model’s capabilities weeks—or even days—later, as HPC-driven updates roll out continuously.
Disclaimers on Architecture & HPC Scale (Grok 3)
Lack of Detailed “Model Card”
xAI has not published a formal white paper specifying Grok 3’s exact parameter count, specialized layers, or full training logs.
Inferences about a “Dense Transformer” design or potential Mixture-of-Experts (MoE) influences stem from prior Grok-1 open-source code (314B param MoE) and partial statements.
HPC Footprint
Grok 3’s enormous training/inference capacity is fueled by “Colossus,” rumored to sustain tens of thousands of GPUs 24/7, possibly at 0.25–0.3 GW usage. xAI cites a 10–15× compute jump over Grok 2.
Critics wonder if HPC scaling alone suffices for a lasting edge, or if diminishing returns will set in. Elon Musk maintains HPC is the surest near-term path to state-of-the-art (SOTA) intelligence.
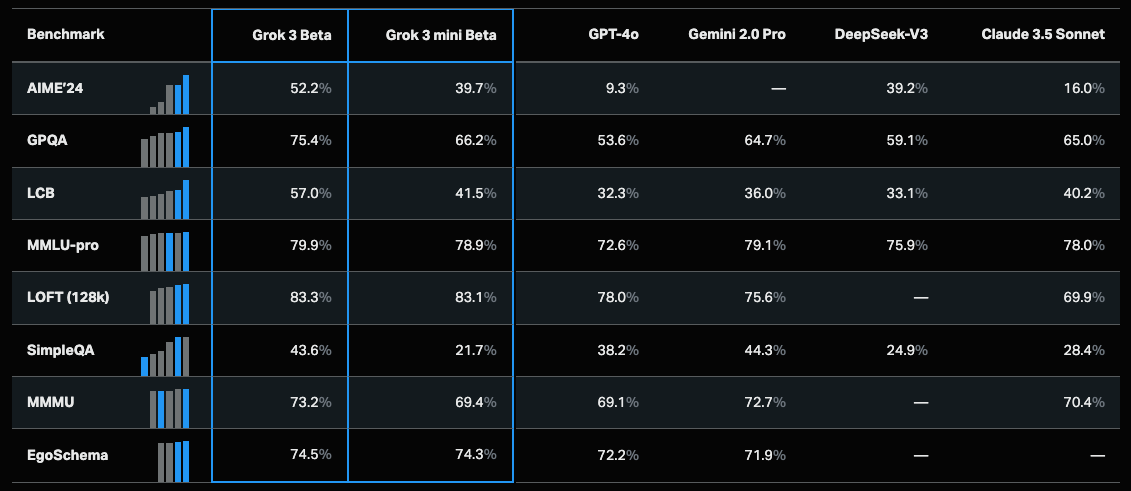
Grok 3: Performance & Benchmarks (Feb 2025)
“Chocolate” on LMArena (1400+ score)
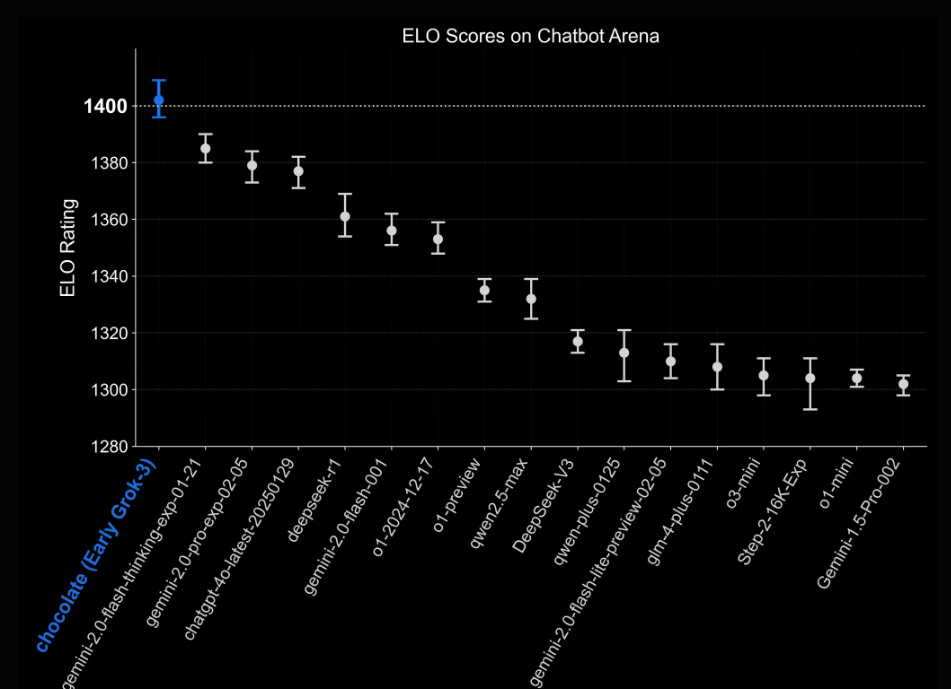
xAI initially deployed an early version of Grok 3 under the covert codename “chocolate” in the “LM Arena.” The LM Arena is an evaluation tool that lets testers query multiple AIs in head-to-head format and vote on which they perceive as the best response.
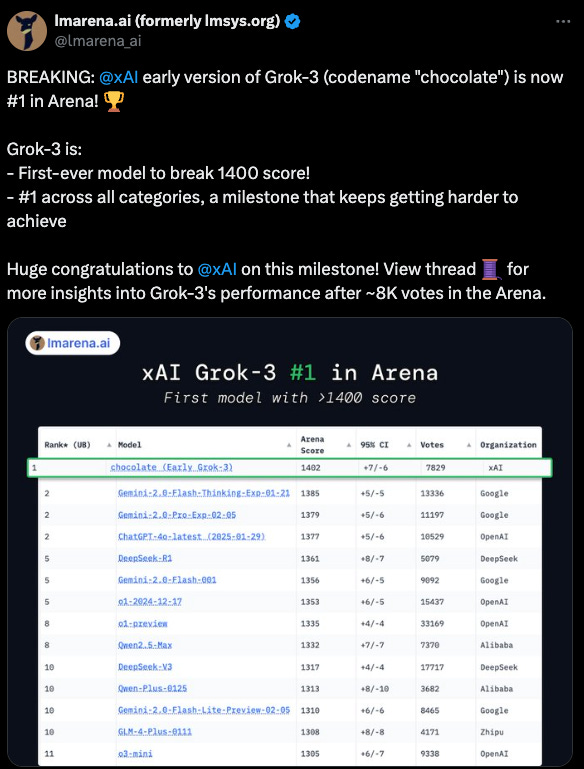
The early Grok 3 (chocolate) achieved an ELO score of 1402… this marks the first time any AI has passed 1400.
Caveats
Some advanced competitor previews (like certain locked “o-series” from OpenAI) may not have faced “chocolate.”
Still, the raw climb in Elo strongly hinted at Grok 3’s robust chain-of-thought, coding, and Q&A prowess.
Math & STEM Proficiency
AIME & Advanced Math
Grok 3 excels on the American Invitational Mathematics Exam (AIME), sometimes hitting scores in the low 90s out of 100—significantly beating older Grok versions. xAI claims it solves fresh 2025 AIME prompts unseen in training.
Observers see it as near the top for pure math tasks, though direct apples-to-apples comparisons often hinge on test-time settings (e.g., multi-response consensus).
Science & “PhD-Level” QA
xAI tested advanced physics, chemistry, or biotech questions. Early user feedback suggests improved multi-step logic, though no formal “PhD test suite” is publicly posted.
HPC re-training might allow quick assimilation of specialized data or user corrections, solidifying domain knowledge over time.
Coding & Reasoning
LeetCode/Codeforces: Beta testers confirm Grok 3 effectively handles coding challenges, from typical data-structure problems to complex dynamic programming. The model can debug or refine code if prompted repeatedly.
Karpathy’s Vibe Check: Andrej Karpathy rated Grok 3 near OpenAI’s “o1-pro” on certain coding tasks after his preliminary vibe check. He praised the xAI team and noted that he’ll be adding “Grok 3” to his personal “LLM council.”
Multi-Pass Logic: HPC capacity also allows “longer chain-of-thought,” e.g., generating multiple solutions, then selecting or merging the best. Some watchers suspect “consensus sampling” is used in certain tasks, inflating success rates on short-answer or coding benchmarks.
My First Impressions of Grok 3 (Feb 2025)

As stated earlier, I really like Grok 3. The more I use it, the more I seem to like it… it’s more addictive to use than ChatGPT (perhaps due to novelty?). It’s responses are extremely fast and I like its ability to pull real-time X-post data from X/Twitter.
That said, some of the data it pulls from X (thus far) is complete garbage. I’m not sure how it determines quality vs. junk… but a few times it cited some trash X post (e.g. social media investors with $ hashtags etc. that gave random uninformed opinions)… I suspect they’ll eventually fix this.
It was not quite as advanced/detailed as o3-mini-high and o1-pro for certain types of queries… however, it held its own and definitely wasn’t getting blown out. Overall I think I currently enjoy using Grok 3 more than ChatGPT… I also preferred its output formatting/breakdowns over ChatGPTs.
Its interface is basically the same as ChatGPT’s… which is smart. People like ChatGPT’s interface so make a variant (this is what DeepSeek did as well).
The “Deep Search” is not as good as ChatGPT’s “Deep Research” but I suspect that it’ll get much better soon. And for the value, I think Grok 3 is a good deal (no brainer if you’re a frequent X user).
Elon is doing his best to get people to switch over to Grok 3 ASAP so that they: (1) take earnings & data away from competitors (OpenAI) AND (2) can generate ROI to reinvest in xAI for improvements.
Big Upgrade from Grok 2 (Obvious)
1 Million Token Context Window: Context window for Grok 3 is 8-fold larger than that of prior models. Grok can process large documents and handle complex prompts while maintaining high accuracy.
Improved Depth & Consistency: Compared to Grok 2, Grok 3 rarely provides half-baked logic or meandering chain-of-thought. Users appreciate fewer abrupt contradictions and better handling of multi-turn instructions.
Inference & Test-Time Compute: xAI aims to make Grok 3 as accessible to as many people as possible with low latency (ultra-fast speed). They also added a “Think” and “Big Brain Mode” that maximize reasoning for complex queries like math/coding.
Self-corrections: Grok 3 can “self-correct” mid-solution as a result of its self-correction loops/mechanism (test-time compute specific).
Speed & ChatGPT-esque Interface
High-Speed for Simple Queries: Straight Q&A or short coding tasks yield near-instant responses. Complex tasks—like multi-file coding or advanced puzzle logic—show a “thinking delay,” presumably HPC overhead for chain-of-thought.
ChatGPT-Style Layout: xAI’s interface mimics ChatGPT’s conversation approach, making it easy for users to adapt. Reusing a well-known format reduces friction for those already comfortable with chat-based AI.
DeepSearch (Decent) & Cost (Reasonable)
DeepSearch References: Grok 3 pulls data from the live web, including random X posts. It can unify contradictory references but occasionally surfaces unverified or speculative content.
Subscription Price Jumps: Premium+ soared from $22 to $40/month in the U.S., with similar 2–3× hikes in the UK and India. xAI cites HPC overhead as the main reason. I think the cost is fair… actually a good deal if you use X.
SuperGrok Rumors: An upcoming tier rumored at $30–$100/month might offer “fewer usage caps,” “Big Brain Mode,” or “unlimited” image generation. The exact usage limits remain unclear.
Competitive Analysis
Nearly Top-Level, Not Universally #1: Grok 3 stands among the strongest LLMs in math/coding. Whether it definitively outperforms all competitor models is under debate—some closed previews from OpenAI or Google remain untested side by side.
Daily HPC Advantage: xAI’s HPC expansions let them respond to user feedback or training data swiftly, potentially overshadowing slower iterative cycles at other labs. Observers see it as an HPC arms race in the AI domain.
Win for Users: Another near-SOTA competitor spurs industry innovation. Over time, the subscription cost might adjust, or specialized tiers might appear, but the short-term effect is a “powerful new tool” for advanced tasks.
Availability & Subscriptions
The 1-2 days after release of Grok 3 they actually raised prices… later they said Grok 3 is now available for free to all users “until our servers melt.”
The X Premium+ and “Super Grok” are priced at ~$300/year though. If you don’t have a paid version you may hit usage limits pretty quick. I was hitting them days ago even with a paid version.
Not sure how pricing will evolve over time… I think they just want as many people trying/using Grok as possible because they’re confident people will like it (I think this is a smart move).
Initial Rollout & X Premium+
Beta Deployment: Right after Grok 3’s February 2025 debut, only X Premium+ subscribers (the $22/month tier at the time) got first access. Users had to update their X app and opt-in to Grok 3’s advanced chat features.
Price Hikes: Within days of Grok 3’s release, the monthly fee for X Premium+ increased from $22 to $40 in the U.S., with similar jumps in other regions: U.K.: ~£17 → £47, India: ~INR 1,750 → INR 5,130, etc. (Not sure what they’ll ultimately settle on here.)
SuperGrok Tier
Standalone or Add-On?
xAI introduced SuperGrok as a new subscription tier—some rumors call it $30–$100/month.
Early internal references mention $30/month or $300/year, but user posts have suggested it might be higher (e.g., $70–$100) for “unlimited HPC usage.”
The exact structure (standalone vs. add-on to X Premium+) is unclear, but xAI’s marketing implies you can purchase it separately if you’re not on X’s ecosystem.
Features:
Big Brain Mode: Extended or multi-attempt reasoning. Some call it “max inference,” letting Grok 3 dig deeper into chain-of-thought.
DeepSearch Upgrades: Higher search rate limits, possibly “unlimited” real-time web queries.
Fewer Usage Caps: Preliminary user reports suggest far fewer daily query restrictions than X Premium+.
Grok Platforms: Website, Dedicated App, X App
Grok.com (Web): Elon & xAI note that if you want the most advanced features of Grok first — use the web version (on your browser).
Often the first platform to receive new model updates or experimental features (like advanced chain-of-thought settings).
Some advanced HPC-driven operations (e.g., big parallel code generation) may appear here earlier than on mobile.
iOS App: There is a dedicated Grok app… and it’s nice. Polished interface but can lag a few days behind the web version for major updates or new modes.
X App: You can also use Grok efficiently on X (the everything app). I prefer using Grok on the web for now… the app is smooth though. Using on X is way better than Grok 2 because it actually analyzes post details accurately (Grok 2 was pretty weak at analysis).
Grok Voice Mode (~1 Week Post-Launch): xAI promises integrated speech input/output, not just standard TTS. HPC overhead might relegate advanced voice features (like continuous conversation memory) to SuperGrok’s top-tier environment.
Grok 3 Debut Presentation: Highlights & Live Demo Recap (Feb 17 2025)
Elon and the xAI team released a ~1 hour presentation of Grok 3 on Feb 17, 2025. This shows how Grok works, some features, and what their plans are with it in the coming days/weeks.
1.) Earth–Mars Transfer Simulation
Prompt & Outcome:
During the official reveal, xAI asked Grok 3: “Generate a 3D Python plot of a spacecraft launching from Earth, landing on Mars, then returning to Earth at the next window.”
Grok 3 wrote approximate code using Matplotlib or similar libraries, incorporating some orbital logic reminiscent of Kepler’s laws. Observers praised how it factored in multi-leg journeys in a single script.
Chain-of-Thought Display:
The demonstration underscored Grok 3’s capacity for domain-level reasoning (basic orbital mechanics) + code generation. HPC re-training presumably helps it handle advanced math references.
2.) “Tetrijes” — Combining Tetris & Bejeweled
Hybrid Game Prompt:
Another official demo had Grok 3 produce a Python game merging Tetris blocks with Bejeweled color matching and scoring combos.
Unlike older LLMs that might produce partial or “Frankenstein” merges, Grok 3’s script generally ran, generating functional gameplay with minimal debugging.
Demonstration Value:
Showed how chain-of-thought steps let Grok 3 unify distinct rule systems. Critics note xAI likely tested “Tetrijes” extensively, but it still highlights multi-step code logic beyond simple cut-and-paste solutions.
3.) Iterative Reasoning & Self-Correction
“Thinking Twice”
In the demos, xAI gave ambiguous prompts or partial corrections. Grok 3 revised code accordingly, explaining changes in layman’s terms.
Beta testers find it less prone to halting or compounding mistakes than single-pass models like older GPT-3.5 or the original Grok 1.
User Enthusiasm vs. Curation
The public was impressed by these polished tasks, though some caution they’re curated best-case scenarios. Real-world queries might highlight different or less ideal performance.
Potential Limitations
Lab-Prepared Demos: xAI likely rehearsed these tasks thoroughly, ensuring minimal error. Observers remain curious about random user prompts that might expose “off-script” weaknesses.
Confidence vs. Accuracy: HPC helps refine chain-of-thought, but Grok 3 can still confidently propose partial solutions if it hasn’t encountered certain corner cases in re-training. Over time, daily HPC cycles might patch these gaps.
Grok DeepSearch: xAI’s “Agentic” Researcher
“Deep Search” on xAI is basically an iteration of Google’s “Deep Research.” Credit to Google for the concept… ChatGPT’s o3-mini-high + “Deep Research” is still the current “research king” because it does a better job analyzing the content its pulling AND the output is more detailed/superior. Perplexity + DeepSeek-R1 “Deep Research” is also a novel variant that does a good job.
Google’s “Gemini” Deep Research is alright, but it doesn’t do a good job providing intricate details, analysis, and gives a cookie-cutter/basic ass output… (the output is detailed if you keep grilling it with further questions, but I don’t like doing this).
Real-Time Web Browsing: DeepSearch allows Grok 3 to fetch data from sites, social media, or official docs in real time. The model then merges the info into a cohesive answer, displayed in a bullet “reasoning panel.”
Partial Transparency: xAI’s UI shows step-by-step retrieval attempts, including URLs or tweet references. This fosters user trust but reveals some data might be unvetted.
Current Weakness
Questionable Citation Quality: The model may incorporate random or unsubstantiated claims from X posts, risking misinformation. There’s no absolute curation layer to guarantee factual correctness. (I think eventually they’ll fix this.)
Comparison to Competitors
Similar to “Deep Research” (OpenAI): Combines LLM + retrieval. Grok 3 is more open, scanning broader or lesser-known sources, but also more prone to questionable references.
HPC Constraints: Real-time search is GPU-intensive (for chain-of-thought expansions). xAI likely gates heavy usage behind SuperGrok or sets daily query limits for normal subscriptions.
Grok Agents?
Domain-Specific “Grok Agents”: xAI teased specialized versions—coding agent, medical agent, etc.—that might integrate curated references from GitHub or PubMed. HPC scaling could swiftly spin these up for paying SuperGrok users.
Refined Citation Formats: Many request deeper referencing or footnote-level citations. xAI says it’s on the roadmap, though they may keep the best features behind premium tiers, citing HPC overhead again.
More Grok 3: Q&A Highlights
Voice & Speech-to-Text
1-Week ETA: xAI announced that voice interactions with Grok 3—both speech input and audio output—will launch roughly one week post-release.
More Than TTS: Unlike simple text-to-speech add-ons, xAI intends a fully integrated approach, letting Grok 3 parse spoken queries and generate spoken answers.
Possible Tier Gating: Observers speculate advanced voice features may require SuperGrok or top-tier Premium+ subscriptions, given the HPC overhead for continuous audio processing.
Memory & Personalization
Longer Context or Session Memory: xAI is experimenting with letting Grok 3 recall user context across multiple sessions, potentially forming a “personalized AI companion.”
Potential HPC Load: Storing and retrieving session data from tens of thousands of concurrent users would be HPC-intensive, raising questions about usage tiers.
User Demand vs. Privacy: Some users desire persistent memory; others worry about how xAI will handle personal data. xAI has not yet published a privacy framework for “session recall.”
Biggest HPC Challenges
Cosmic-Ray Flips: At the scale of 100k–200k GPUs, cosmic rays can flip bits in GPU memory. xAI reportedly has fail-safes, repeated checks, or partial re-trains to mitigate large-scale corruption.
Cooling & Power: Liquid cooling loops must handle the continuous load from HPC training, while Tesla Megapacks smooth out abrupt GPU demand spikes. The Memphis facility overcame an initial 15 MW power limit to exceed 120 MW usage.
Model Identity & Ethics
Grok’s “Gender?”: xAI’s stance: “Grok is whatever you want it to be.” They half-joke about users forming emotional bonds.
Tackling Big Math (Riemann?): xAI teases that HPC + chain-of-thought might eventually address open math problems like the Riemann Hypothesis.
Open-Sourcing Strategy
This is consistent with my thought that “open source” is just straight up dumb if your goal is to win the AI race. The only people benefitting from open source are labs that are not in the lead. Open source is great, but feeling entitled to it (after others bust their ass $/energy figuring out the architectures) is a communist mindset.
No Grok 3 Release: xAI has committed only to open-sourcing Grok 2 “once Grok 3 matures.” The timeline is unclear—some expect a 6–12 month wait.
Protecting Frontier Secrets: xAI’s pivot away from immediate open-sourcing contrasts with earlier claims of openness. Observers link it to Elon Musk’s emphasis on monetizing HPC-driven breakthroughs.
xAI (Grok 3): The Memphis “Colossus” & HPC Feat
The xAI crew explained why and how they setup the “Colossus” supercluster in Memphis.
Why Build a Custom Data Center?
Rental Limitations: GPU rentals from typical cloud providers offered too few GPUs and quoted 18–24 months lead times. xAI needed a 100k-GPU cluster now.
In-House Advantage: By developing the “Colossus” site in Memphis, xAI gained full control over cooling, networking, and server configurations, an approach few AI labs attempt at such scale.
122-Day “Impossible” Buildout
Aggressive Timeline: Engineers from competitor labs called a fully liquid-cooled HPC center in 4 months “impossible.” Elon Musk pushed 24/7 shifts, using mobile cooling trucks and massive generator arrays.
Doubling to 200k H100s: After the first 100k GPUs, xAI nearly doubled capacity in another ~92 days. This HPC “shock and awe” tactic underscores Musk’s willingness to outspend or out-hustle conventional HPC timelines.
Liquid Cooling & Tesla Megapacks
Why Liquid Cooling? Dense GPU racks generate huge heat. Conventional air-cooling would be too inefficient. xAI deployed custom liquid loops across thousands of servers to maintain stable temps.
Megapack Buffering: HPC workloads can spike power demand in milliseconds. Tesla Megapacks smooth out these fluctuations, preventing local grid overload or brownouts.
Ongoing 1.2 GW Expansion
Aiming to 5× Capacity: xAI aims for ~1.2 gigawatt usage at Memphis, potentially overshadowing many HPC data centers globally.
Skepticism & Cost: Rival labs question if HPC alone yields a stable advantage or if it’s financially sustainable. xAI counters that HPC is essential for daily re-training and real-time chain-of-thought inference.
Jensen Huang’s “Superhuman” Praise
Nvidia’s CEO Reaction: Jensen Huang commended xAI’s data center deployment speed, calling it a “superhuman feat.” Skeptics see the accolade as partial marketing or synergy with Nvidia’s GPU sales.
Implications for AI Race: By proving HPC expansions can happen in mere months (vs. years), xAI sparked an arms race. Labs that can’t keep pace risk lagging behind in the push for bigger or more frequently updated models.
Grok 1 → 3: The Path So Far

Early Grok Versions
Grok 1 (314B param, MoE): xAI once open-sourced it, but it was overshadowed by other SOTA LLMs at the time, partly due to HPC constraints limiting training durations.
Grok 1.5 & 2: Showed incremental leaps. Observers noted promising results on coding tasks, but the HPC-limited training left them behind GPT-4 or Claude 3.5 in many benchmarks.
The 17-Month “Quantum Leap”
HPC-Limited to HPC-Driven: Once “Colossus” launched, xAI scaled from Grok 2 to Grok 3 using ~10–15× more compute. Performance soared, with xAI citing near-vertical leaps in “MMU” vs. time.
Synthetic Data & Chain-of-Thought: Elon Musk mentioned reliance on synthetic data generation plus advanced chain-of-thought training. Some watchers suspect a minimal role for RL, focusing on HPC brute force.
Reinforcement or Not?
Debates on RL: Observers differ: some see Grok 3 using partial RL for reasoning modes, others claim xAI invests in HPC scaling + curated data sets. xAI has not clarified.
Chain-of-Thought Gains: Regardless, Grok 3’s multi-step self-correction and “reasoning loops” overshadow older single-pass approaches from Grok 1–2.
Future Grok 4 (Speculation)
Size: 1T-1.5T parameters, 32-48 experts, leaner base model.
Capabilities: Multimodal (text, images, audio) with real-time reasoning; enhanced test-time scaling (e.g., dynamic “Big Brain” mode).
Compute: Colossus at 300k GPUs, optimized for low-latency inference, continuous X-data updates.
Focus: Inference efficiency over raw scale—smarter expert routing, longer thinking on tough queries.
Edge: Deep X integration, proactive insights; aims for speed and relevance, not just size.
Timeline: Late 2026, building on Grok 3’s 2025 beta.
Speculation: xAI shifts from parameter bloat to runtime mastery, making Grok 4 a fast, adaptive research partner—less about being the biggest, more about outthinking rivals in real time.
Related: Top 8 AI Labs Ranked for Inference Scaling (Feb 2025)
xAI’s Mission & “Zero-to-1?”
Grand Vision: “Understand the Universe”
xAI positions Grok 3 (and future versions) as tools to probe cosmic-scale questions—e.g., alien existence, cosmic beginnings/ends, the nature of reality.
Elon Musk’s philosophy holds that a “maximally truth-seeking AI” must be free from excessive guardrails or political correctness if it’s to make genuine discoveries.
Following a Paved Road
Earlier Labs Blazed HPC Trails: OpenAI, Google DeepMind, Anthropic, and others have proven large-scale HPC for AI yields big leaps. xAI embraced these insights, focusing on extreme HPC scale from day one, circumventing earlier trial-and-error phases.
Potential MoE or Hybrid: Rumors persist about Grok 3 using a Mixture-of-Experts structure or a dense Transformer architecture with chain-of-thought enhancements. No official doc confirms this, but it’s widely speculated from Grok 1’s MoE background.
Could xAI Forge Its Own Paradigm?
Musk’s Track Record: Tesla overcame skepticism with battery-driven EVs, Starship overcame “impossible” mass challenges. xAI could similarly pivot if HPC saturates, adopting or inventing new model frameworks (like continuous learning “living architectures”).
Grok 3 as Bridge: For now, Grok 3 stands as a prime example of HPC’s near-term potential, bridging conventional Transformer scaling with iterative chain-of-thought. xAI hopes this momentum paves the way for an eventual “zero-to-1” leap beyond standard LLM paradigms.
Grok 3 Recap (Feb 2025)
A.) Grok 3’s Significance
Major HPC-Fueled Challenger: By amassing ~200k H100 GPUs in Memphis, xAI rapidly iterated from Grok 2 to near-SOTA levels. Grok 3’s coding, math, and daily improvement cycles demonstrate HPC scaling’s power.
Opaque but Impressive: xAI hasn’t disclosed a detailed architectural white paper, which frustrates some. Nonetheless, curated demos like Earth–Mars transfers and “Tetrijes” prove advanced multi-step logic well beyond older Grok versions.
B.) “Colossus” Ripple Effect
Arms Race in HPC: Rival labs face pressure to expand HPC or refine new, more efficient architectures. The AI landscape is shifting to “faster HPC + daily updates.”
Commercial Secrecy: xAI’s approach to keep Grok 3 closed, with minimal official data, suggests a deeper focus on monetization and competitive advantage.
C.) Not Necessarily #1, But Near-SOTA
Leading in Some Benchmarks: On advanced math (AIME) and certain coding tasks, Grok 3 ranks near the top, though exact comparisons to locked competitor models remain partially untested.
Daily HPC Edge: If xAI continuously refines chain-of-thought or domain data, it could surpass or tie top closed previews (like advanced OpenAI “o-series” or Gemini 2.0 Pro). Rival labs might accelerate their update cycles in response.
D.) User & Enterprise Perspective
Steep Subscription Tiers: $40/month for X Premium+ (up from $22) and the rumored $30–$100/month for SuperGrok. Not bad. Currently Grok 3 is free for everyone (this may change).
Innovation Catalyst: Another strong competitor fosters a dynamic marketplace, potentially driving more advanced features, new safety/ethics considerations, and eventually more consumer-friendly pricing.
Grok 3 AI: Critiques & Feedback (Grok 3: Feb 2025)
It’s important to understand that some people dislike/hate Elon and want him to fail so readily talk shit and/or are overly critical of anything he releases.
I don’t think most criticisms were excessive for Grok 3… most seemed fair and acknowledged that the model is high-level.
Many critiques may also be a bit premature because they rolled out Grok a bit early and realized they had some tuning to do over the next 7-10 days… perhaps a re-testing then would be smart.
Benjamin De Kraker on Grok 3 for Coding (ex-xAI engineer)
I understand Benjamin was being a good guy sharing his honest opinion… but when you work at xAI, it’s probably best to avoid ranking your model (which wasn’t completely finalized) lower than competitors and sharing this publicly ahead of its release.
Why? AI is a highly competitive sector and marketing/psychology matters a lot (it’s cutthroat)… each lab tries to generate ridiculous hype when a new model is released (OpenAI does this in a somewhat cringeworthy way sometimes).
Anyways, I doubt anyone at OpenAI, Anthropic, DeepSeek, Gemini etc. would think of posting subjective rankings with competitors’ AI models ahead of theirs prior to full public release (even if they are objectively better). This is something best kept on the DL (to yourself).
If I work at Coca-Cola but post about how Pepsi is better or something, it’s not a good look. Nevertheless, I wish Benjamin nothing but the best and applaud his intellectual honesty.
So what happened?
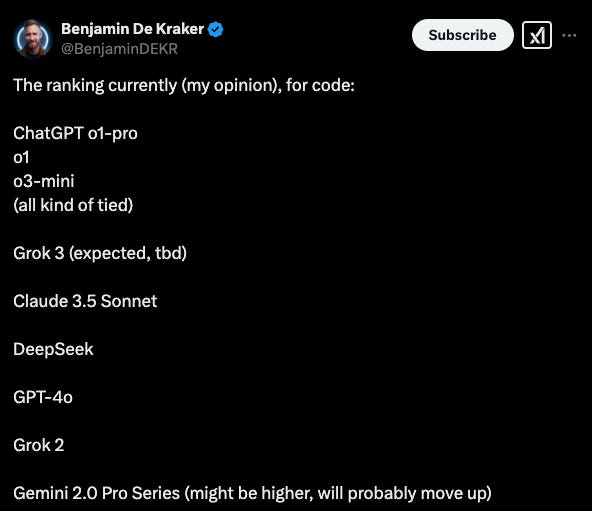
A former xAI engineer posted his subjective rankings of current AI models — placing ChatGPT (o1-pro, o1, o3-mini-high) at the top with Grok 3 next.
xAI allegedly demanded he remove references to Grok 3’s uncertain standing. Rather than removing his subjective rankings, he resigned from xAI.
The dispute underscores xAI’s protective stance around Grok 3’s image.
AIME 2025 Score Comparisons (Teortaxes Edition)
A smart AI analyst on X going by the moniker Teortaxestex created a chart showing side-by-side performance of top AI models on AIME (American Invitational Mathematics Examination)… a math benchmark.
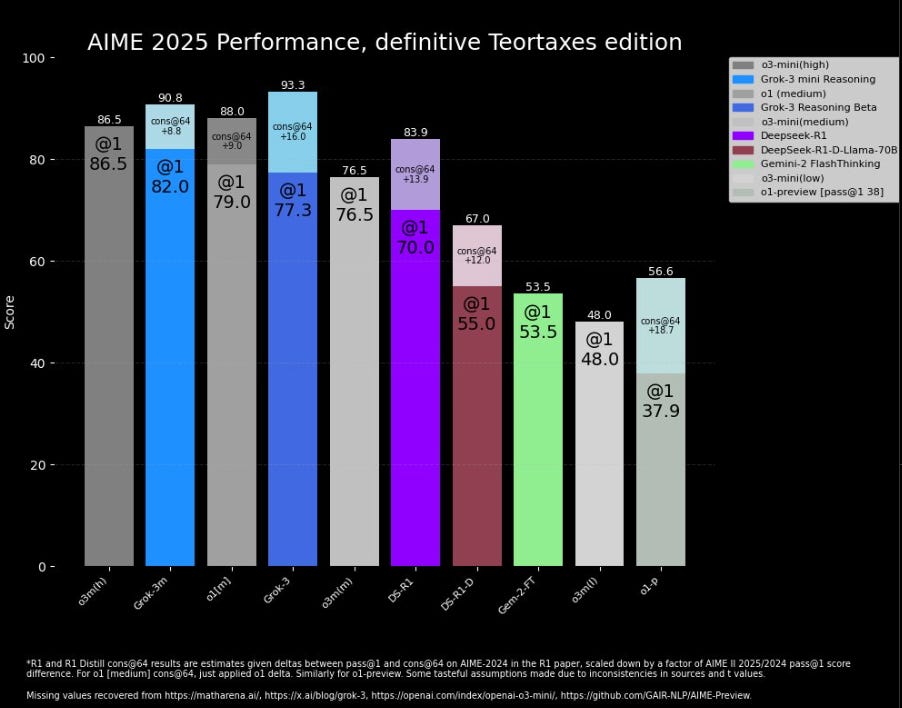
Reported Scores
Grok 3 Reasoning allegedly around 93.3, grok-3-mini near 90.8.
OpenAI’s o3-mini-high: 86.5; o3-mini-medium: 76.5; o3-mini-low: 48.
Observers note differences in test-time configs (e.g., “cons@64” for Grok 3 vs. baseline single-pass for competitor models).
Chart Manipulation?
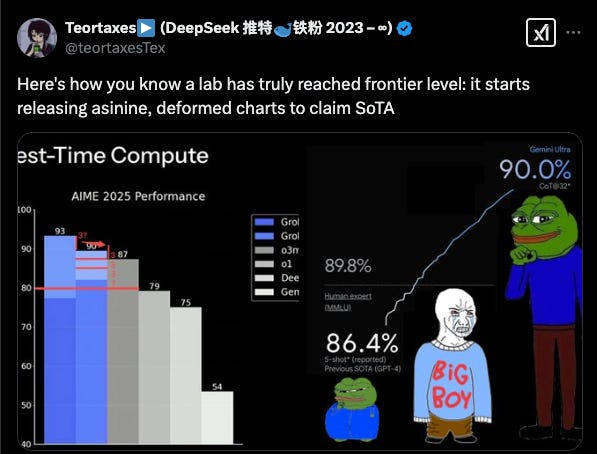
Many claim xAI exaggerates small numeric leads using visually “stretched” bar charts. xAI counters that all advanced LLM labs do some marketing spin (including OpenAI).
This is a common thing for AI companies and non-AI companies… it’s a psychological and marketing warfare out there… Some think that Tesla manipulates FSD data and presentation for the sake of psychology/marketing too.
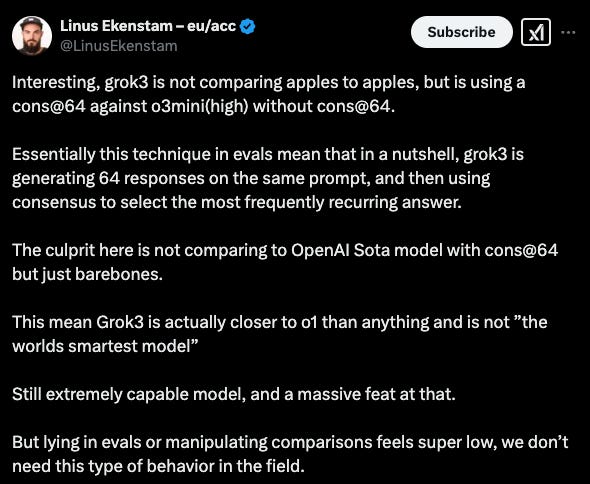
Possibly Unfair Comparisons

Consensus vs. Barebones: If Grok 3 uses multi-sampling or chain-of-thought expansions (like Big Brain Mode), competing models tested in baseline mode might underperform by comparison.
Real-World Utility: Even if some benchmarks are inflated, many testers confirm Grok 3’s coding/math abilities are genuinely top-tier and highly competitive for daily usage.
Balanced Takeaways
A High Performer, Not Unchallenged: Grok 3’s near-SOTA performance is tangible, but not unequivocally #1 in every domain.
Marketing Tactics: xAI’s secrecy and strong claims lead some to suspect “benchmark massaging.” Nonetheless, HPC-driven daily improvements do yield real results.
Final Thoughts on Grok 3 & Competition (Feb 2025)
Try it for a couple days and use your own judgment. Give Grok 3 a legitimate shot. Initially I was like it’s alright, pretty good… then later I was like wow it’s really enjoyable to use and I like it. Damn good.
I don’t think it’s “THE BEST” but some do. Best is somewhat subjective and based on how you are using these models… and what you value (speed, X post references, output formatting, output style/tone, etc.).
Something you could do (what I’ve been doing) is have Grok 3 open next to ChatGPT — and whenever I have a query, I just paste it into both… and then compare the outputs. They are very competitive. Even if Grok 3 isn’t the best I think I like its output style more.
Then again, I also like the upgrade ChatGPT recently made to its 4o model… does a way better job than before… but the real-time data that Grok 3 is pulling is great. I think most people who try Grok 3 will really like it.
And remember, Grok 3 will keep getting better (it wasn’t even finalized when released)… don’t bet against Elon. He’s highly motivated after feeling wronged by OpenAI and going for the jugular. Love to see this competition.
I expect more AI engineers to be poached by Elon/xAI, NVIDIA racks going brrr at Colossus, and a 1 million GPU supercluster (eventually). My mentality aligns with Elon’s… architectural optimizations won’t beat raw computing horsepower.
Keep optimizing a Toyota Prius engine and get lapped by a Pagani Zonda… or maybe if you’re Altman you’d drive a Koenigsegg Regera. (I’ll admit my mentality could be off-base, but the "software optimization” people seem woke and naive. If you can “just optimize” then why don’t you just buy a single NVIDIA GPU and catch up?)
Sure there may be some GPU threshold needed to compete… but I still think: all labs have similar talent/high IQs, most have similar understandings of the AI literature/innovations (can adapt rapidly)… so the only real “MOAT” is hardware.
Who can accumulate the most of the best hardware, engineer optimal hardware setups/optimizations, and make maximum use of the hardware (none of the hardware should be just for display… gotta actually use it or “fill it out”).
The thing with hardware is you can’t just copy it and “make it” on your own. You need to rely on companies like TSMC, ASML, AVGO, SNPS, CDNS, or whatever… and you need to have the budget to pay for it, integration software, etc. This isn’t easy… hardware is the most difficult thing to replicate because even if you have the mass design, good luck locking down the supply chain and getting mass production.
Anyways, in the U.S., the AGI/ASI race is heated… OpenAI and Google were “chillin” basically singing kumbaya and playing footsie… DeepSeek said TF y’all been doing? And dropped a tactical nuke with R1… now Elon and xAI are putting other AI labs in a pressure cooker and turning up the heat. OpenAI is readying the release of GPT-4.5 & GPT-5 though (could be soon).
You can really tell who is feeling the pressure based on how much they: advocate for pausing/stopping AI development, express concern about “alignment” or “ethics” or “safety,” and how angry they get if competitors don’t “open source” cutting-edge/SOTA models.
I think Elon harps on OpenAI for being “ClosedAI” and not open because he feels slighted and because he’s trying to throw chaos at them to overtake them… I don’t think he really cares if they’re open/closed as long as xAI wins… but part of the reason he’s doing this is because they are legitimate competition.
If they weren’t, nobody would even care or talk about OpenAI. Claude is constantly expressing concern for “safety” (they are free to do so but others aren’t required to follow in their ultra-woke footsteps)… they still have some elite talent and will likely stay in the fight though.
Meta keeps lagging (maybe they’ll do something eventually? I wouldn’t hold my breath… but they are crushing it with AI-related advertisement optimizations on the biz side of things).
What about the Chinese? DeepSeek, Qwen, Doubao, Hunyuan, Ernie. Chinese labs could make some crazy optimizations and stay in the race (some smart people think they could pull ahead with UltraMem & NSA (Natively-trainable Sparse Attention)… but we’ll evaluate after implementation (not fantasize about what they might do).