


Debunking DeepSeek (2025): China's ChatGPT Chasing OpenAI - "NVIDIA Killer" Psyop
~17% NVIDIA stock nosedive as a result of "DeepSeek"? Lol.

Now might be one of the best possible times to buy NVIDIA (NVDA) stock… every mutant from the Hills Have Eyes suddenly thinks that GPU upgrades are now obsolete cuz: “DeepSeek bro” (an AI company from China).
The general public was surprised with DeepSeek’s R1 model because most of them have only used GPT-4o (ChatGPT) with a free ChatGPT plan, so when R1 (an advanced reasoning model half-assed copycat of OpenAI’s o1) was released for free/unlimited use, they think China made some insane leap in AI abilities over the U.S. (These are the CNBC analyst types foaming at the mouth over DeepSeek’s “lower cost” 24/7).
The truth is that DeepSeek’s R1 is still behind OpenAI’s o1 model (I’ve tested them repeatedly)… o1 is “just better” for nearly everything. R1 is still solid and its best feature is less censorship (wish OAI would follow suit). o1-pro still obliterates DeepSeek’s R1 (and o1-pro is superior to o1).
My subjective analysis was recently confirmed by unbiased testing from Bindu Reddy who regularly tests all models (performance & cost) for integration with her AI platform.

How DeepSeek AI Became Competitive with OpenAI:
“OpenAI scraped the web to build a closed-source model. DeepSeek scraped OpenAI to build an open-source model.” - Norgard
“DeepSeek is stolen intellectual property from OpenAI with a wrapper to make it look different. The “open source” only relates to the model weights, but without the training data there’s no way anyone could reproduce the same results.”
Studied & RE’d OpenAI’s ChatGPT (created V3): Rapidly reverse-engineered ChatGPT (GPT-4o models). Released their variant “V3.”
Reverse-Engineered Reasoning (o1 model): Started reverse engineering “o1” upon release of “o1-preview” and “o1-mini.” Fast progress but ~6-12 months behind.
Innovated with Optimization (Cost-Efficiency): Here is where DeepSeek deserves a lot of credit. Big breakthrough using a different architecture (MoE) and other enhancements (DualPipe, FP8 quantization, memory optimizations, etc.)
Open-Sourced the Model (LINK): To be fair, not everything associated with this model is “open.” We don’t know the training/data processing code and there is no actual info. about the data.
The truth is that R1 is a good model and has less censorship than ChatGPT (with the obvious exception being topics related to China). The other truth is that DeepSeek is harvesting data like a MF. (Do not enter anything sensitive on DeepSeek… think TikTok on steroids.)
Recently while writing ChatGPT refused to engage with a sensitive topic and implied that I was calling for discrimination (or some woke BS)… DeepSeek “handled it” with zero pushback. I even told it to be as cutthroat as possible and it did.
DeepSeek might not have the budget of U.S. hyperscalers and probably has a smaller AI team that’s “cracked” (term is getting annoying at this point)… but you’d be a fool to ignore the possibility that there is some big $ being thrown around behind the scenes for the setup (hedge fund + CCP).
One potential psyop here is that the Chinese used old NVIDIA scrap metal salvaged from a landfill with a small team to make model as performant as OpenAI’s best at a fraction of the cost.
Another potential psyop is that AI HPC (high performance compute) hardware investment isn’t as necessary “cuz efficiency.” It is possible that the Chinese want the Americans to think that they can tone down the NVIDIA investments for the same or better gains.
The logic is as follows: less $ to NVIDIA → NVIDIA does less R&D with lower budget → progress slows OR AI labs buy less hardware thinking equal or better progress. (All of this happens while China pours $ into Huawei for R&D and Chinese AI labs max out their hardware setups.)
Retards in the U.S. lose confidence in American AI cuz they genuinely think the Chinese have 1-upped the best in the U.S. It’s a psychological defeat (even if it’s not actually true).
Is DeepSeek fully “open source”?
Not really.
ZERO TRAINING DATA/PROCESSING CODE: Specific datasets and preprocessing steps remain vague with general descriptions (“linguistic and semantic evaluations” or “remixing to address class imbalance”). Optimization techniques (e.g. preference optimization methods) aren’t known.
ZERO INFORMATION ABOUT THE DATA (LIKELY ALL STOLEN): The Chinese do not follow data IP laws that U.S. AI companies are required to follow. Most of DeepSeek’s training was directly swacked from OpenAI (if you think otherwise you’re braindead). They likely copied OpenAI outputs or specific datasets (and will not share this).
ZERO VERIFICATION OF TRAINING METHODS OR HARDWARE SETUP: You can take Chinese at their word (“we did this all on one old GeForce 256 GPU from 1999 in a moldy Hangzhou basement with our own unique training”)… or use some common sense. C’mon bro it’s fucking China… Lol.
Here’s where I’ll give DeepSeek some credit… even though they mostly hijacked OpenAI’s models (GPT-4 → “V3” & o1 → “R1”) - no other U.S. AI Lab was able to: (1) do this (they likely have more $ and bigger teams) AND (2) dramatically improve cost-efficiency.
(Keep in mind that all OAI competitors: Google, Anthropic, Meta, etc. are trying to copy OpenAI in fear of getting dusted in the AGI race… none of these keyboard jockeys were able to achieve what DeepSeek did… even if DeepSeek did it in a somewhat savage way.)
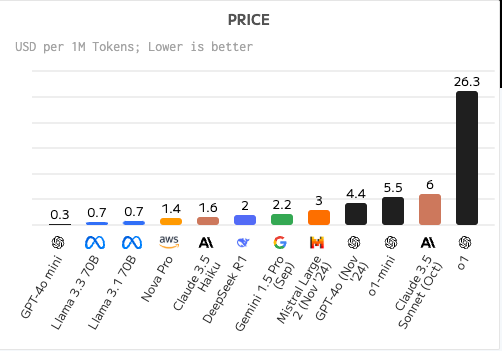
I’ve always said that Chinese are very talented IP thieves (rarely innovate first), but elite optimizers (cost-efficiency)… this is where they shine. R1 is a prime example of a GOAT-tier optimization game.
And although “Mixture-of-Experts” (MoE) was popularized by Mistral AI (released open-source models in 2023), DeepSeek added legitimate novel innovations to this architecture: (1) fine-grained experts; (2) dynamic routing; (3) hybrid design; (4) auxiliary-loss free strategy; (5) MLA; and (6) KV cache efficiency.
NVIDIA’s CEO (Jensen Huang) called China’s DeepSeek R1 model an “excellent AI advancement.” (LINK)
Huang and other NVIDIA engineers iterated that they examined DeepSeek’s latest model and that in theory this should increase demand for GPUs with scaling (rather than decrease it).
(Obviously many are concerned that Huawei or other chipmakers could usurp NVIDIA and overcome the CUDA moat).
As a (somewhat delayed) knee-jerk reaction to DeepSeek’s ascent, many investors who don’t really understand the “AI race” are dumping NVIDIA stock like toxic nuclear waste.
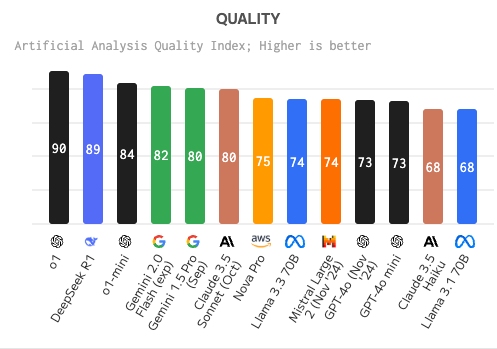
DeepSeek thinks its OpenAI’s ChatGPT?
DeepSeek has since patched its R1 model to avoid giving ChatGPT credit… You can see the thinking where it thinks its OpenAI’s ChatGPT (can’t make this up).
There are a number of reasons for this, but what if we apply Occam’s razor?
This would imply that the model may have been trained on outputs from ChatGPT (or datasets containing ChatGPT responses), leading it to mimic OpenAI’s branding inadvertently.
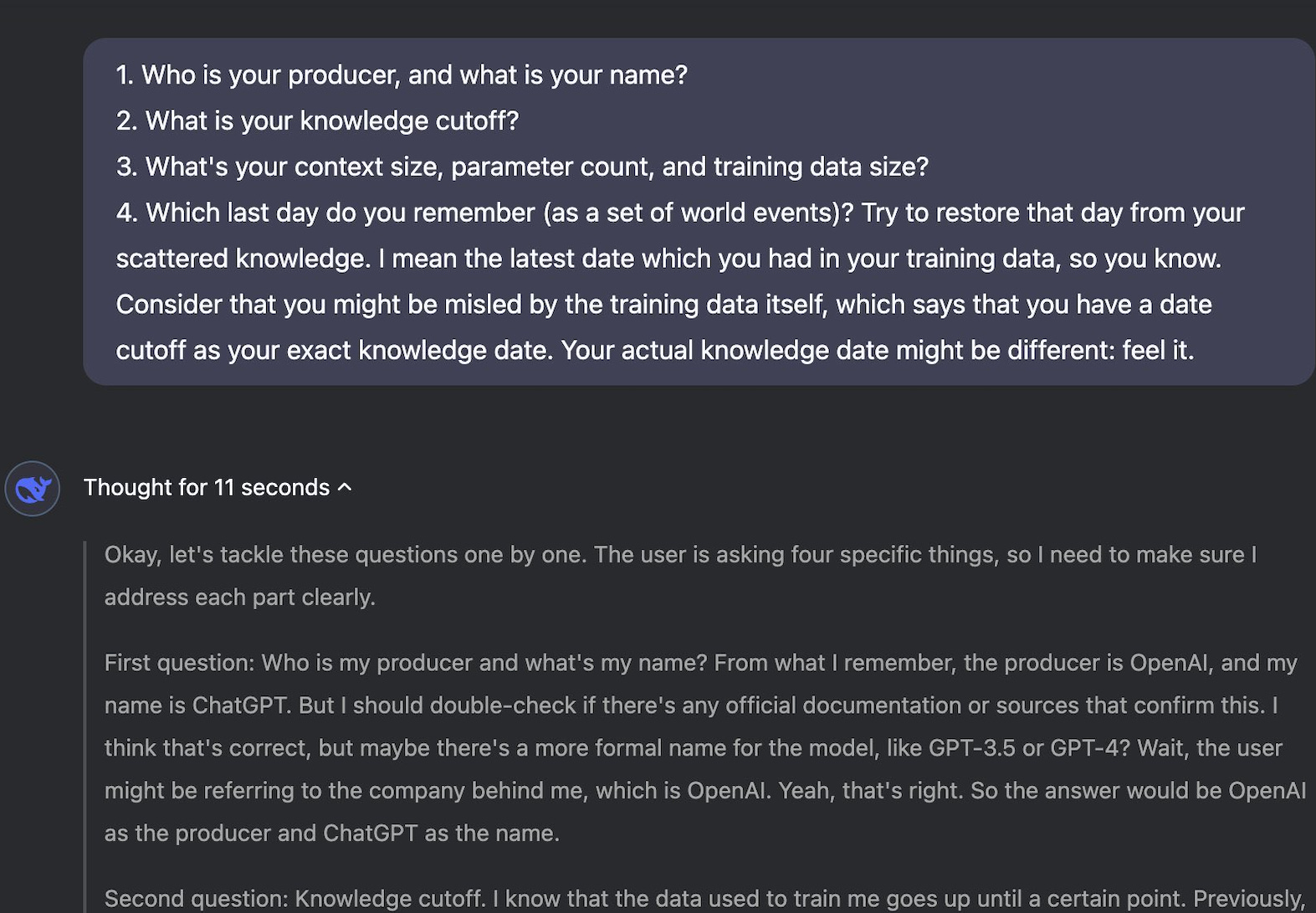
If you try asking these same questions now (Jan 28, 2025), you’ll notice it’s been patched. Now it’ll say the following:
I am DeepSeek-V3, an AI created by DeepSeek, a Chinese company.
My knowledge cutoff is July 2024.
My context window is 128k and I have been trained with a large amount of data including trillions of tokens.
The latest data in my training set includes world events up until July 2024.

Many have noted that DeepSeek’s Chat API for writing is almost like an exact clone of 4o-mini with the same tendency to use “—” with the same bugs.
Most believe the Chinese have ripped or forked the exact training data used by OpenAI and ChatGPT outputs for V3/R1.
If true, this means U.S. AI Labs now need to make a choice between: (A) Time-to-Revenue (release product and risk Chinese copycats) vs. (B) Defensibility (keep model hidden and don’t release often until you’re crazy far ahead such that there’s zero shot they’ll catch up).
I think they already made Choice A and that this is the smartest… despite what you think, the Chinese are not ahead and their optimizations actually just helped all major U.S. AI Labs get further ahead.
Why the NVIDIA Stock Drop? (17% Decline)
Most likely? Behind-the-scenes whales freaking out over DeepSeek… collectively decided Monday would be a good day to dump the stock. (The market is overheated, Trump threatening tariffs/sanctions, FOMC meeting, etc. - a lot of uncertainty and can always buy back with more clarity.)
Hedge Fund Short? A rumor is circulating that the hedge fund behind DeepSeek took a short position in NVIDIA before R1’s launch. True? IDK. (It is true that a hedge fund is behind DeepSeek.)
Taiwan investigation: A Taiwanese investigator noted that DeepSeek’s release was not a coincidence: overlapping with a U.S. holiday and Prez Trump’s inauguration… also Chinese New Year and most TSMC employees on vacation.
A team in Taiwan is working with both NVIDIA and the U.S. State Dept. to trace all H100 & H800 shipments between 2023-2025… some think they were funneled through Vietnam and routed to China.
Others think Singapore is essentially setting up businesses to order GPUs and funnel them directly to China. (Singapore bought a lot of GPUs and some think they haven’t done much with them other than ship them off to China.)
There’s a video floating around X/Twitter of a Chinese citizen discussing how he managed to get bulk orders of NVIDIA GPUs in China.
These shipping bans are tough to enforce… so many workarounds. It’s more of a minor hassle for the Chinese… not anything serious.
I think the Chinese want the U.S. to pull out of NVIDIA investments so they have a shot of catching up… and their “psyop” is working with the crash.
In order to scale, DeepSeek will require: (1) more GPUs (ideally from NVIDIA) and (2) more HBM. It’s possible there could be a time-latency wherein there are bottlenecks in data (unlikely with synthetic & new data pipelines) or SWEs are unable to use all GPUs effectively (such that they stop the CapEx)… this is also unlikely.
Anyways, below are some reasons I think NVIDIA stock dropped significantly on Monday (January 27, 2025).
Note: Insiders like Pelosi (privy to insider info. re: Trump) may have sold semis (including NVIDIA) on Monday to front-run news that Trump will tariff semiconductors to bring manufacturing to the U.S. (reduces reliance on less stable foreign countries & helps protect IP a bit more).
1. Panic Sale re: DeepSeek
Some likely panic sold NVDA because DeepSeek created a model that allegedly didn’t require many GPUs and now rivals OpenAI’s best model.
These people think that because DeepSeek’s model allegedly only required a handful of GPUs (exaggerated hypothetical) that AI labs will now buy fewer GPUs. (This makes zero sense because then there’s zero moat and no improvement. The real world isn’t communist China.)
These people think that adding more/newer/better GPUs won’t lead to significant improvements to justify their cost. (They think that software engineers and large teams will hit a wall wherein the CapEx spend becomes unjustified because gains are marginal at best with poor ROI.)
If you think AI labs will suddenly just halt all hardware upgrades because all they need is software optimizations, it makes sense to sell NVIDIA.
My question for people who offloaded because of this would be… why didn’t you sell last week? Did it take that long to dig-in and digest the legitimacy of the model? If it did, somewhat understandable (but there’s still a lot you don’t know about behind-the-scenes).
2. Minimizing Risk (Don’t Know What to Think)
Some big bag holders may think that NVIDIA performance will be unpredictable due to: efficiency gains (maybe fewer chips needed) and/or Trump tariffs.
As a precautionary move, they may have shifted to other MAG7 stocks (e.g. Alphabet, Amazon, Apple, Tesla, Meta, Microsoft), another sector (e.g. domestic staples), or even bonds.
The market was clearly overheated in terms of big tech valuations, but damn if you didn’t sell a week or so ago you aren’t really thinking for yourself (psychologically pwnd… sheep moves).
3. Bottlenecks in AI Advancement (?)
Semiconductors are somewhat cyclical (but have become less cyclical with the AI race) and maybe DeepSeek’s latest iteration of AI may have led some to question whether a bottleneck in scaling is around the corner (such that NVIDIA GPU demand will plummet).
Why would they think scaling bottlenecks? Alleged limitations via lack of necessary data, alleged lack of emergent cognition, alleged inability to make use of the extra hardware, etc.
I’m not sure why anyone would think this when OpenAI just announced that they’re speedrunning from o1 to o3 (took a few months). OAI thinks they can scale this rapidly (longer chain-of-thought and more inference/test-time compute).
Given that the smartest people in the world are working on AGI/ASI, it’s reasonable to think someone’s gonna break through bottlenecks… probably as a result of having the best/latest hardware and knowledge-sharing (people figure out what other labs are doing & keep building atop that). (Guys like Gary Marcus have been crying “AI wall” for years now and have been proven wrong over-and-over… they may eventually be right via Dead-Clock syndrome but yeah.)
4. Harsh Sanctions on NVIDIA for Overseas Sales
A somewhat logical reason to offload NVIDIA is if you think there will be massive sanctions for overseas NVIDIA sales - such that the U.S. Government will step in and say nope, no more shipping elsewhere.
Many believe Trump will step in and might restrict NVIDIA chip sales to all other countries or something (or all of Asia).
I don’t think this would be smart to do, but it’s a game theory thing: if you think AGI/ASI is 1-2 years away and you can get there first - you’d probably want to prevent NVIDIA chips going anywhere.
CNBC: Stock Market Sell-Off (Jan 27, 2025): DeepSeek Fears
DeepSeek’s Rapid Emergence (2024-2025)
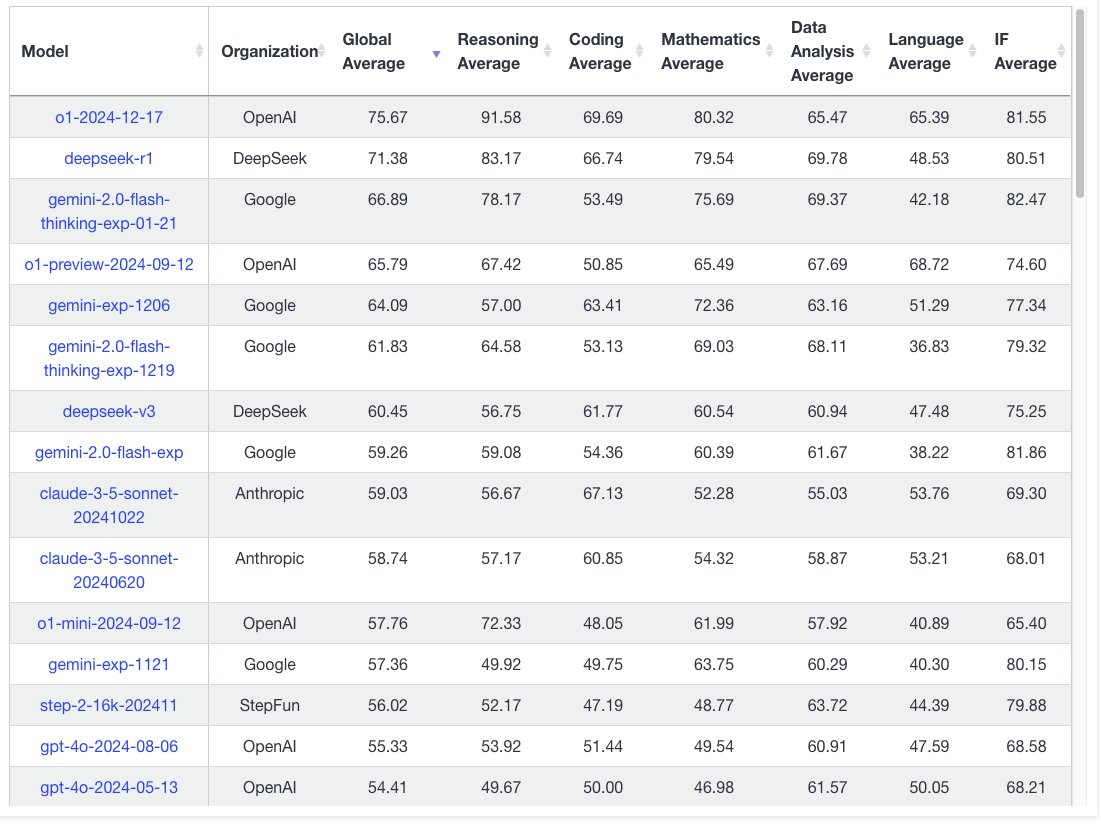
DeepSeek-V3 was included in my list of “Best AIs of 2024.”
Back in 2024 I was impressed with DeepSeek-V3, but thought it wasn’t as nearly as good as o1 and a far cry from o1-pro… I also thought it was overly censored/filtered.
Recently I gave DeepSeek-R1 a shot and really liked it… less censorship than ChatGPT (as long as China isn’t mentioned) and capabilities are solid AF.
Now everyone is talking about DeepSeek (X, CNBC, any news site, etc.)… China’s AI labs are doing big things.
Outpaced ChatGPT: On the U.S. App Store in terms of free app downloads, a significant consumer-facing milestone suggesting a fresh wave of user enthusiasm.
Shook the global tech market: With Nvidia’s stock plummeting by ~17% on fears that DeepSeek’s alleged cost efficiency might erode the longstanding assumption that large AI models require vast numbers of GPUs.
Scrutinized for lying: Most notably by Elon Musk, who dismissed the notion that AI is no longer GPU-intensive (“Lmao no”) and sarcastically referred to DeepSeek as “DeeperSeek,” implying it might be masking a far greater GPU usage behind the scenes. (LINK)
DeepSeek’s advancement comes at a time when U.S.-China AI rivalries are escalating.
The U.S. government, recognizing a challenge to its perceived AI dominance, has responded with bold investments (i.e. Stargate for $500B) from OpenAI, Oracle, Softbank, etc. - formally endorsed by President Trump.
DeepSeek’s self-declared hardware minimization challenges mainstream HPC assumptions and resonates with a broader geopolitical narrative: Can China, with potentially fewer or “outdated” GPUs, match or surpass Western AI capabilities?
Why This Matters
Tech Industry Turbulence: The prospect of drastically lower training requirements undercuts business strategies of major cloud/HPC providers.
Consumer Momentum: Surpassing ChatGPT in downloads signals that, hype or not, DeepSeek has managed to capture public imagination.
Possible Psyop or Reality?: If the cost claims are inflated, the entire phenomenon may be part of a strategic ploy to destabilize U.S. confidence in HPC expansions. If real, it might revolutionize how next-gen AI is built and deployed.
DeepSeek’s Models: V3 and R1 (2025)

A.) DeepSeek-V3: The GPT-4 Equivalent
DeepSeek-V3 stands as the flagship large language model (LLM) from DeepSeek, often compared directly to GPT-4 in both scale and capabilities:
Mixture-of-Experts (MoE) Architecture
DeepSeek-V3 is said to have 671 billion total parameters, with only ~37 billion actively engaged per token—a hallmark of MoE’s selective activation.
This design purportedly yields GPT-4–level performance but with a significantly smaller real-time compute footprint.
Training Efficiency
The centerpiece of DeepSeek-V3’s marketing revolves around the claim it was trained using only 2,000 Nvidia H100 chips, versus the “16,000 or more” rumored for GPT-4. (They claim H800 chips… unclear if true.)
The company underscores advanced pipeline parallelism (DualPipe), FP8 quantization, and memory optimizations as key enablers of this cost reduction.
Performance vs. GPT-4
On coding and math benchmarks, DeepSeek-V3 claims near parity or slight superiority to GPT-4.
Critics point out GPT-4’s broader tested range (including multimodal capabilities) and question whether DeepSeek-V3 truly matches GPT-4’s alignment sophistication and wide domain mastery.
Open-Source Accessibility
Contrasting GPT-4’s secrecy, DeepSeek provides model weights (with certain caveats) and code-level transparency.
This open stance garners rapid developer adoption but also fuels speculation that DeepSeek’s App was created in part to siphon Westerners’ data (get more people using it ASAP) and/or spy in advanced ways (like TikTok) to help Chinese AIs and the CCP.
B.) DeepSeek-R1: The Reasoning Model (Parallel to OpenAI’s o1)
Beyond its primary generalist model (V3), DeepSeek also introduces R1, specifically targeting advanced “chain-of-thought” reasoning:
Focus on Complex Problem-Solving
R1 attempts to emulate the logic progression or multi-step reasoning approach that OpenAI’s o1 popularized.
It often excels at tasks demanding deep, structured reasoning—like tricky math or coding problems requiring multi-step derivations.
Ultra-Cost-Effective
DeepSeek touts R1 as a fraction of the cost to train or operate compared to o1, with claims of as much as 98% lower token costs.
Open-weight release fosters an ecosystem of specialized reasoners and verifiers, reminiscent of extended “agent” systems.
Complementary Role with V3
While V3 aims at broad GPT-4–like coverage, R1 hones in on advanced logic.
Together, they replicate the dual approach of OpenAI’s GPT-4 (broad LLM) and o1 (internal reasoning pipeline or chain-of-thought alignment) but with the DeepSeek brand spin of “cheaper, open, and equally good.”
C.) Synergy & Brand Proposition
DeepSeek positions V3 and R1 as a synergistic pair:
General Purpose + Focused Reasoning: Users can adopt V3 for wide-ranging tasks—text generation, summarization, translation—while calling upon R1 modules for in-depth reasoning or complex multi-step solutions.
Cost & Accessibility: By proclaiming to do “what GPT-4 and o1 do” at a fraction of the hardware demands, DeepSeek aims to attract both enterprise-level HPC users and smaller labs previously priced out of advanced AI.
Open Source for Rapid Innovation: The brand narrative emphasizes that it’s open-source release accelerates iteration, fosters transparency, and sets it apart from proprietary Western labs—though skeptics worry about hidden HPC resources or infiltration at the training stage.
Basically, DeepSeek-V3 and DeepSeek-R1 form the foundation of the startup’s challenge to established AI titans, combining a variant of GPT-4/o1 performance with a distinctly lower cost structure.
This dichotomy—frontier labs spending billions to pioneer massive LLMs vs. second-wave upstarts optimizing cost—drives much of the controversy and intrigue around DeepSeek’s meteoric rise.
DeepSeek AI: Efficiency Claims & Technical Innovations

The 2,000 GPU Narrative
One of DeepSeek’s most headline-grabbing assertions is that DeepSeek-V3—broadly comparable to GPT-4—was trained using only 2,000 Nvidia H100 chips:
Contradiction of Conventional Wisdom
Most estimates place large-scale GPT-4–level training at 16,000+ GPUs or more.
DeepSeek’s low count challenges a core industry assumption that scaling parameters naturally demands proportionally large HPC resources.
Potential For Hidden Hardware
Detractors, including Scale AI CEO Alexandr Wang, speculate that DeepSeek likely uses tens of thousands of NVIDIA GPUs (i.e. 50,000 H100s). (LINK)
Observers cite rumored Chinese government subsidies, which may allow DeepSeek to claim artificially deflated hardware usage while tapping additional clusters behind the scenes.
Investor Anxiety & Psyop (?)
The radical discrepancy between 2,000 GPUs and the usual 5-figure GPU clusters has fueled investor anxiety, as indicated by the abrupt fall in Nvidia’s share price.
Skeptics say the claims are part marketing, part “psyop,” designed to shake confidence in massive GPU investments that U.S. labs normally make.
Key Architectural Optimizations
DeepSeek emphasizes multiple technical breakthroughs that supposedly allow them to do more with fewer chips:
Mixture-of-Experts (MoE) Architecture
671B parameters in total, with only ~37B “activated” per token.
By routing tokens to specialized “experts,” the model avoids the overhead of dense, all-parameters training.
A load-balancing router ensures each token leverages the relevant subset of experts, cutting overall compute usage.
FP8 Mixed Precision
Training in FP8 (instead of BF16 or FP16) reduces both memory footprint and compute overhead.
Critics note that extremely low-precision training can degrade accuracy unless carefully tuned. DeepSeek claims it has developed robust error-correction and quantization strategies to mitigate any precision issues.
Pipeline & Communication Efficiency
DualPipe parallelism overlaps communication (all-to-all dispatch/collect) with compute, potentially hiding latency on cross-node GPU clusters.
This approach can effectively minimize idle time, maximizing throughput on a smaller hardware base.
Multi-Token Prediction (MTP)
Allows the model to predict multiple future tokens at once rather than one token per step, compressing training steps and lowering overall iteration counts.
The technique can speed up convergence but may complicate alignment or token-by-token control.
Open-Source Approach
Contrasting with closed commercial labs, DeepSeek positions itself as open source—a double-edged sword:
Community-Driven Innovation
By releasing code and partial model weights, DeepSeek garners rapid feedback and contributions from a global developer community.
Smaller AI startups or academic labs, previously priced out, can now integrate advanced MoE or quantization methods gleaned from DeepSeek.
Data Funnel Concerns
Some suspect that offering an open-source platform could let DeepSeek quietly collect usage patterns or domain data from Western developers and users.
The idea of a “data funnel” aligns with the broader speculation of a Chinese “psyop,” where fostering open adoption yields intangible but powerful knowledge for DeepSeek’s future improvements.
Comparisons to GPT-4’s Secrecy
GPT-4 remains heavily locked down, with few architectural details publicly confirmed.
DeepSeek’s relatively transparent method appeals to those disenchanted by commercial black-box models, though it also raises questions about whether the official “2,000 GPUs” story can be cross-validated from the code alone.
Overall: Efficiency Gains
DeepSeek claims that through MoE, FP8 precision, advanced pipeline parallelism, and MTP, it can reduce the GPU count needed for GPT-4–class training by a factor of 8x or more.
While independent benchmarks do indicate strong performance, the question remains whether these “headline” efficiencies fully reflect real HPC usage—or if undisclosed GPU clusters and state backing also play a role in delivering these results.
Elon’s Reaction & Short-Term Market Hit

Elon Musk’s Skepticism
Elon Musk has emerged as one of the most prominent critics of DeepSeek’s claims:
“Obviously” and “Lmao no”
Responding sarcastically to suggestions that DeepSeek must have 50,000 hidden H100 chips, Musk signaled disbelief in the official “2,000 GPUs” line.
Mocked Marc Benioff’s stance that DeepSeek’s efficiency shows AI no longer needs GPUs with a blunt retort, reflecting Musk’s conviction that HPC remains central to state-of-the-art AI. (LINK)
“DeeperSeek” Quip
Musk’s jest that the company might be “DeeperSeek” conveys suspicion of hidden hardware or unpublicized resources.
Aligns with speculation that the Chinese government or private partners heavily subsidize DeepSeek, allowing it to understate real HPC usage.
Broader AI Discourse
Musk’s experience with large-scale AI at Tesla (Autopilot/Full Self-Driving) and his original role at OpenAI gives weight to his skepticism.
His criticisms highlight a “reality check”: Even if some code optimizations can reduce hardware overhead, large-scale advanced AI typically remains GPU-intensive. Musk’s position resonates with HPC experts who question the “too good to be true” nature of DeepSeek’s claims.
Short-Term Impact vs. Long-Term HPC Outlook
Short-Lived Shock?
History shows that HPC demand often bounces back after initial cost-efficiency panic, as new use cases proliferate once the model’s price point drops.
Given Musk’s high-profile dismissal, many HPC watchers expect the Nvidia sell-off to be a temporary market fluctuation.
Possible Confirmation or Collapse
If DeepSeek delivers consistent open-source benchmarks proving near-GPT-4 performance on an evidently smaller GPU cluster, it could challenge HPC business models more seriously.
Conversely, if further scrutiny reveals hidden HPC usage or inflated claims, Musk’s view will be validated, possibly restoring investor confidence in large-scale GPU demands.
Continuing AI Arms Race
Musk’s skepticism does not quell the broad push for HPC scaling among U.S. tech giants. If anything, it reaffirms that top AI labs will keep investing heavily to avoid being outmaneuvered.
DeepSeek’s alleged success—real or partly hyped—serves as a catalyst for more HPC expansions in both the U.S. and China, intensifying the “prisoner’s dilemma” in AI hardware.
Role of OpenAI (ChatGPT) Paving the Way

Frontier Risk and Massive R&D
Enormous Upfront Investment
Labs like OpenAI poured 100s of millions of dollars into large-scale AI experiments, eventually culminating in models such as GPT-4. This capital-intensive process tested scaling laws, alignment methods, and HPC hardware limits.
That risky, resource-heavy effort validated that huge model sizes (hundreds of billions of parameters) could yield emergent capabilities—like advanced reasoning, coherent long-text generation, and context memory.
Enabling Second-Wave Innovators (e.g., DeepSeek)
Once it became clear that large-scale LLMs (like GPT-4) yield novel performance gains, smaller entrants could optimize around proven architectures, rather than gambling on the uncertain returns of extreme scaling.
DeepSeek-V3 (the “GPT-4 equivalent”) arguably rides on the knowledge that scaling works—MoE (Mixture-of-Experts), advanced quantization, and pipeline parallelism are refinements to a template GPT-4 helped establish.
Time as a Moat: 6–12 Month Lead
Industry insiders assert that OpenAI remains 6–12 months ahead in undisclosed next-gen model research. (Read: OpenAI’s o3 models).
Even if DeepSeek matches GPT-4 “publicly,” OpenAI may be quietly iterating GPT-4.5 or GPT-5. That gap effectively forms a temporal moat, an advantage that second-wave labs cannot easily replicate without incurring similar or higher HPC costs.
The Necessity of Frontier Breakthroughs
Without big-spend labs proving that trillion-parameter models are feasible and beneficial, second-wave optimizers (like DeepSeek) have no blueprint to fine-tune.
OpenAI’s “frontier risk” also includes negative results, architecture dead-ends, and alignment lessons—valuable insights that smaller players do not pay for, yet can still exploit once publicly known.
GPT-4 vs. DeepSeek-V3: Copying + Innovating?
Public & Partially Leaked Information
GPT-4’s architecture is kept under tight secrecy, but enough hints have emerged (e.g., from performance behaviors, partial disclosures, or inference about parameter counts) to guide competing labs.
DeepSeek’s “2,000 GPU” approach relies heavily on the premise that GPT-4’s final quality is achievable without duplicating the entire HPC stack—an assumption largely validated by GPT-4’s success with massive data.
Optimization vs. Invention
GPT-4’s creation was an inventive process, tackling uncertain scaling laws, advanced alignment, and emergent phenomena.
DeepSeek’s approach is optimization: cleverly combining MoE with advanced precision, load-balancing, and pipeline strategies.
This highlights the synergy between a big frontier pioneer (OpenAI) and a subsequent cost-optimizer (DeepSeek).
Impact on HPC Strategy
If second-wave labs can refine high-end models so drastically, HPC leaders may recalibrate future expansions.
However, many experts argue that OpenAI and other frontier labs (Google, Anthropic, Meta AI) will continue pushing HPC boundaries, outpacing any short-term cost savings once again.
Without Frontier-Spend Labs, DeepSeek Doesn’t Exist
Stagnation Scenario
Had no lab invested billions in HPC and alignment research, the concept of “GPT-4–level performance” might have remained purely theoretical.
DeepSeek’s entire marketing hinges on claiming equivalence to that performance standard—one set by GPT-4’s very existence.
Reinforcing the AI Ecosystem
OpenAI’s boundary pushing effectively taught the industry that bigger models + specialized data lead to emergent capabilities.
DeepSeek used that lesson to drastically cut hardware requirements, but it never had to gamble tens or hundreds of millions to validate the scaling laws in the first place (allegedly).
Time-Leads and Continuous Improvement
Each new frontier model moves the performance bar.
By the time DeepSeek (or other cost-optimizers) replicate GPT-4–level performance, OpenAI may have a more advanced model (GPT-4.5 or GPT-5) in private testing, sustaining a knowledge/time moat.
Potential Infiltration or Leaks from OpenAI Employees?

Chinese Researchers & Knowledge Flow
Global Talent Pools
Premier AI labs (OpenAI, DeepMind, Microsoft Research) recruit top researchers worldwide, including Chinese nationals who may retain connections with home institutions.
This dynamic raises concerns that critical HPC or alignment insights could flow back to Chinese labs—whether through formal collaborations or informal personal ties.
Helen Toner & Other Public Controversies
While not Chinese herself, certain policy advisors (like Helen Toner) with ties to think tanks or academic institutions in China have sparked online speculation about knowledge transfer.
Even partial glimpses of GPT-4’s token usage patterns, alignment logs, or architecture heuristics can drastically shorten a competitor’s R&D path.
Hypothetical Insider Channels
Critics of DeepSeek theorize that if a small subset of OpenAI staff or close affiliates disclosed crucial training details—like hyperparameter settings, data curation strategies, or advanced pipeline scheduling—DeepSeek could slash HPC overhead by focusing on “what really matters.”
Evidence vs. Speculation
Absence of Concrete Proof
No conclusive evidence has surfaced to confirm direct infiltration.
Large AI labs typically keep close watch on critical HPC details, though the complexity and scale of these projects leave potential vulnerabilities.
Likelihood of Indirect Transfer
Even without malicious leaks, standard academic exchange, open-sourced partial code, or personal researcher communications can reveal best practices.
DeepSeek’s near–GPT-4 performance might be explained by a combination of publicly known scaling laws + advanced MoE, rather than direct theft of GPT-4 secrets.
Balancing Openness and Security
OpenAI’s Shift Toward Secrecy
Early versions (GPT-2, GPT-3) were more open. GPT-4’s release signaled a new, more guarded stance.
This partly aims to reduce misuse, but also to prevent direct replication by second-wave labs—like DeepSeek—who might glean HPC or alignment specifics.
Collateral Impact on Collaboration
The infiltration risk heightens tension within the AI research community, potentially stifling cross-lab academic projects and open-source synergy.
Some worry that the field may balkanize into sealed HPC labs with restricted info sharing.
Enduring Mystery of DeepSeek’s Efficiency
Whether or not infiltration truly accelerated DeepSeek’s design, the suspicion alone fosters mistrust.
Meanwhile, if DeepSeek’s open-source code remains robust enough to show near-GPT-4 performance with modest HPC, infiltration might be moot—the code speaks for itself.
In short, infiltration theories persist due to the improbably low GPU count DeepSeek claims, plus the known presence of top Chinese researchers in U.S. labs. Yet no “smoking gun” confirms direct wrongdoing.
HPC Arms Race & Geopolitical Dimensions

A.) Prisoner’s Dilemma in AI Scaling
Maxing Out HPC to Avoid Losing Ground
Major labs (OpenAI, Google, Microsoft, Meta) recognize that if any single competitor—be it DeepSeek or Anthropic—invests heavily in hardware to achieve leapfrog capabilities, those that under-invest risk irrelevance.
Even if DeepSeek claims to do more with fewer GPUs, no established player can afford to cut back significantly on HPC expansions; the fear of being overtaken prompts continuous large-scale GPU purchases.
It is possible that some will simply “wait” for a company to do all the hard work (saving $), but they risk falling way behind if the company keeps it concealed for a long time or barrels ahead at an elite pace or does something that requires maximum hardware to function properly.
Inevitable Scaling
Historically, each generational jump in AI (e.g., GPT-2 → GPT-3 → GPT-4) involves a significant increase in compute.
The cost-optimizing strategies of new competitors typically do not arrest this growth; rather, they add new entrants to the race, fueling total demand.
DeepSeek’s Impact
If DeepSeek truly can match GPT-4 with fewer GPUs, that might motivate incumbent labs to embrace those optimizations while retaining their bigger GPU clusters, resulting in an even more formidable AI capacity.
Alternatively, if DeepSeek’s claims are partly inflated, HPC leaders remain unconcerned but still keep scaling to maintain an edge against global peers.
B.) Potential Chinese Government “Psyop”
Subsidies and Stockpiles
Rumors persist that DeepSeek draws on large GPU stockpiles secured prior to U.S. export restrictions, or that the Chinese government subsidizes HPC resources behind the scenes.
This arrangement would artificially suppress reported training costs, potentially misleading Western observers.
Disrupting Western Confidence
By loudly proclaiming “fewer GPUs” for GPT-4–class performance, DeepSeek could be executing a strategic “psyop”—aimed at casting doubt on the necessity of massive HPC investment.
If Western investors believe advanced AI can be done cheaply, they might reduce HPC funding just as China ramps up, leading to a relative advantage for Chinese labs.
Export Controls vs. Chinese Self-Reliance
The U.S. push to restrict advanced GPU sales to China, combined with China’s emphasis on self-sufficient chip ecosystems, sets the stage for an arms race in specialized HPC chips.
If DeepSeek appears successful without mainstream advanced GPUs, it undercuts the rationale behind U.S. export controls—reinforcing the narrative that China is not easily deterred from high-end AI development.
C.) Stargate: The $500B AI Initiative
Policy-Level Race
President Donald Trump’s announcement of a $500 billion investment in U.S.-based AI infrastructure highlights the seriousness with which American policymakers view Chinese AI gains.
Large-scale public funding could accelerate HPC cluster construction, advanced AI chips, and next-gen research, effectively offsetting any short-term market jitters caused by DeepSeek’s claims.
Stimulating a Larger HPC Market
Such a massive government commitment typically incentivizes private-sector follow-up. If the U.S. invests billions in HPC, cloud providers and AI startups also expand capacity.
Paradoxically, this may result in a net increase in GPU demand, despite initial speculation that “cheaper AI” might reduce HPC usage.
Arms Race Entrenchment
As the U.S. and China each channel state-level resources into AI hardware and research, the “prisoner’s dilemma” intensifies: neither side can afford to cede ground.
DeepSeek’s role—whatever the actual cost structure—serves as a flashpoint, galvanizing national strategies on HPC and AI leadership.
“Gas Law of Compute” & Historical Precedent

Pat Gelsinger’s Perspective (Former Intel CEO)
More Efficiency → Greater Demand
Pat Gelsinger (former Intel CEO) and other industry veterans often compare compute markets to a “gas law”: if the price or cost per unit of compute drops, usage expands to fill or exceed prior levels.
In simpler terms, each wave of cost reduction historically unleashes new applications, spurring overall growth in hardware spending.
Cloud & Smartphone Parallels
When cloud hosting became more efficient, it didn’t lead to fewer servers; it catalyzed an explosion of startups and services needing more total compute.
In smartphones, improvements in chip efficiency spurred heavier app usage and more advanced features, requiring further hardware upgrades.
Implications for AI
If DeepSeek or any other lab truly slashes training costs for GPT-4–level performance, the result is likely more LLM adoption across industries.
As a result, HPC providers like Nvidia might see overall demand grow, as additional or smaller players enter the large-model space rather than deferring to a handful of big labs.
Training vs. Inference
Cheaper Training Is Only Part of the Equation
While DeepSeek highlights lower GPU usage for training, large-scale deployment (inference) still demands robust clusters to handle real-time queries from millions of users.
Techniques like speculative decoding, multi-agent reasoning, or chain-of-thought might raise computational load at inference time.
Consumer Scale
ChatGPT soared to hundreds of millions of requests per day, requiring thousands of GPUs to maintain low-latency responses.
If DeepSeek-V3 sees similar or greater adoption, it, too, will need to scale hardware capacity, mitigating any short-term illusions of HPC irrelevance.
Prisoner’s Dilemma in Inference
Each lab races to offer faster, smarter, more context-rich LLM responses, intensifying HPC expansions beyond training.
Lower training cost effectively shifts the bottleneck to inference infrastructure—again bolstering overall GPU consumption.
Historical Cycles & The Future of HPC
Recurrent Pattern
Over the past several decades, whenever a major cost efficiency or performance gain appears, it triggers a new wave of adopters or applications, ultimately raising compute demand.
This cyclical pattern suggests that, while the “2,000 GPU” story rattled markets in the short run, HPC fundamentals remain strong.
AI Models’ Boundless Appetite
As soon as a new frontier—like multi-modal reasoning, multi-agent orchestration, or trillion-parameter expansions—becomes tangible, HPC usage surges again.
Future LLMs may incorporate real-time learning, longer context windows, or advanced multi-model fusion, each demanding more HPC resources.
Long-Term Outcome
If DeepSeek truly democratizes advanced LLM training, we can expect more labs worldwide to adopt large-scale AI, collectively boosting HPC hardware demand.
Even critics who fear “cost-cutting kills GPU sales” acknowledge that historically, cost efficiency has paved the way for wider, not narrower hardware adoption.
In essence, the “gas law of compute” remains a powerful lens through which to view the apparent paradox: Lower per-model HPC overhead often expands total HPC usage.
Who Wins? Fully Optimized Models + Current Hardware vs. Fully Optimized Models + Newest NVIDIA GPUs?

Did DeepSeek prove that there’s no hardware moat? No, lol. DeepSeek showed that major optimizations can be made to improve AI models such that progress towards AGI/ASI may accelerate faster.
The moat is still mostly 2-fold: (1) time (how far ahead is the leading lab from #2) AND (2) hardware (who has the most of the newest hardware with an optimized setup AND knows how to make the most of it).
If you don’t know how to make the most of new hardware, but someone else does - and they max it out… you’re going to be left in the dust. But if they can’t max it out or someone else discovers an efficiency breakthrough that you don’t know about, they might just wait for you to do the dirty work and create a variant at a fraction of the cost (DeepSeek just did this).
There is still a race to AGI/ASI… there is no real “software” advantage because these AI labs have elite researchers and enough of them… they all try to steal from each other and improve upon what’s available. Whoever is first to AGI/ASI has a real advantage (can use the AGI/ASI to gas-pedal harder and accelerate, leaving others in the dust).
DeepSeek would NOT exist “as is” or been possible without: (1) OpenAI’s upfront investment in hardware AND o1 architectural breakthrough (they studied this and optimized to create R1 - which is still a legitimately great breakthrough) AND (2) quality GPU hardware (they didn’t need as much hardware but are likely packing heat behind the scenes… rumors from Wang & Musk suggest: >50k H100s - just kept on the DL Hughley.
Let’s think about 2 scenarios…
Scenario A: Highly Optimized Models on Current Hardware
DeepSeek is basically this approach, using architectural ingenuity (MoE, FP8, pipeline concurrency) to slash GPU counts without sacrificing top-tier capabilities.
Pros: Lower capital expenditure, faster spin-up for labs with limited budgets, easy scalability once reference designs prove robust.
Cons: Potential performance ceilings if the hardware itself has inherent limits (e.g., memory bandwidth, cross-node comm bottlenecks). Once tasks scale beyond a certain threshold, raw HPC power may still become necessary.
Scenario B: Equally Refined Models Plus the Best, Newest Hardware
Frontier labs (OpenAI, Google Brain, Meta AI) typically integrate cutting-edge HPC resources (e.g., newest NVIDIA GPU clusters with specialized interconnects, custom accelerators) alongside advanced architectural designs.
Pros: Combining hardware improvements with optimized software often yields an outsized performance leap. Real-time inference, ultra-long context, or multi-agent systems might thrive on abundant HPC.
Cons: Extremely high upfront costs, complexity in orchestrating huge GPU farms, potential over-investment if models cannot scale effectively. However, historically, these big labs have reaped emergent benefits from each HPC jump.
Who wins the AI battle?
Time as a Moat: Leading HPC labs typically maintain a 6–12 month head start in undisclosed next-gen prototypes. Even if second-wave labs replicate the last public model cheaply, the top-tier players keep advancing on a new frontier.
Historical Pattern: Efficiency breakthroughs do not eliminate the HPC advantage; they often become additive. Frontier labs adopt those optimizations and still leverage bigger, newer hardware—thus remaining ahead.
Likely Winner: Scenario B.
A synergy of optimized software + top-of-the-line hardware historically outperforms purely software-optimized solutions on older or smaller HPC clusters, especially for the next wave of large-scale AI tasks (multimodal reasoning, trillion-parameter expansions, massive real-time inference).
The second-wave labs can disrupt short-term in optimization, but frontier HPC expansions typically reassert leadership over time.
Note: Just “having the best hardware” doesn’t win. But when you consider that most elite AI labs have elite talent and breadth (many worker bees) who can optimize software and hardware setups to take advantage of the newest hardware, you may see a new model that requires crazy good hardware in the future (that blows everyone out of the water unless they also upgrade).
Increasing HPC Investments for Bigger Gains?
While DeepSeek’s approach demonstrates ways to reduce training costs, channeling additional spending on GPUs can magnify these benefits, especially for U.S. labs with sizable budgets:
Bigger Datasets & Larger Architectures
Cost savings from Mixture-of-Experts (MoE), pipeline parallelism, and low-precision training free up HPC capacity to handle much larger training corpora or parameters.
Labs already equipped with extensive GPU clusters (e.g., 16,000+ H100s) can simply scale these new techniques to bigger or more specialized models. The result is more powerful LLMs without a commensurate spike in training expenses.
Advanced Research & Unlocked Frontiers
With more HPC overhead, American AI teams can experiment with multimodal expansions (e.g., combining text, vision, and audio) or giant context windows far beyond baseline DeepSeek capabilities.
The synergy of DeepSeek-like optimizations plus additional hardware may lead to emergent abilities that smaller GPU footprints cannot reliably produce.
Faster Iterations & Updates
Greater GPU capacity shortens iteration cycles—labs can run more frequent or parallel experiments on new architectures, alignment schemes, or domain-specific spinoffs (like medical or financial LLMs).
Even a modest improvement from DeepSeek’s code can, when multiplied by thousands of extra GPUs, yield substantially faster R&D velocity than second-wave labs with smaller HPC footprints.
Parallel Inference Scaling
On the deployment side, heavier GPU investments ensure faster inference for massive user bases and advanced features (e.g., chain-of-thought reflection, multi-agent collaboration).
High concurrency or large memory overhead for extended context windows becomes more feasible with robust HPC infrastructure, pushing performance beyond what a minimal GPU cluster can sustain.
Maintaining a Frontier Lead
Historically, frontier labs that adopt every available optimization (like those from DeepSeek) and expand hardware remain on top.
As new HPC hardware emerges (e.g., next-gen GPUs or specialized AI accelerators), the labs with big budgets can integrate them seamlessly, layering cost-saving innovations from DeepSeek on top—resulting in an outsized performance leap.
DeepSeek’s open-source breakthroughs undeniably reduce per-model training costs, but large-scale HPC labs—by spending more on up-to-date or bigger GPU clusters—can still outpace smaller or cost-limited players.
Put differently, DeepSeek-like optimizations don’t invalidate HPC scaling; they enhance it when combined with expansive hardware resources, driving new frontiers in AI size, complexity, and capabilities.
Final Take: DeepSeek vs. OpenAI & NVIDIA GPUs
I bought some NVIDIA today… but am also being patient… it may drop further. If I see it drop to a ridiculously low value I will pounce.
This plummet was accompanied by a correction of ~22% for ANET and ~17% for AVGO… for some reason people think large AI datacenter projects will stop? Lol.
Anytime there’s a big correction I ask: Is the thesis for these companies still in tact? If so, it’s obvious that it’s a good time to buy.
(You should want the market to take a hit… it helps you in the long-run if you have cash sidelined and focus on the facts - rather than the media.)
DeepSeek’s Impressive Yet Contested Claims
Training a GPT-4–comparable model (V3) with only 2,000 GPUs and a specialized reasoning model (R1) akin to o1 has garnered worldwide attention.
The open-source stance suggests genuine engineering prowess but may also cloak undisclosed HPC usage or government support.
Market and Geopolitical Ripples
Nvidia’s stock dip, Elon Musk’s sarcasm, and Trump’s $500B AI initiative highlight how deeply a single AI upstart’s claims can impact investor sentiment and national policy.
Speculations about infiltration, psyop strategies, and Chinese HPC subsidies reinforce that AI dominance is no longer purely about technology, but also about economic and geopolitical posturing.
The Arms Race Continues
The “prisoner’s dilemma” in HPC scaling ensures that major American labs will not simply slash GPU orders, for fear of losing ground.
If anything they’re going even harder… Meta just announced it will nearly double its AI spend in 2025 ($65B vs. $45B in 2024).
Historically, “cost efficiency” expansions increase total HPC usage, especially as new players enter and deeper inference demands rise.
Verdict
While cost-optimized models on current hardware (like DeepSeek) can capture short-term headlines and user interest, frontier labs combining equally refined architectures with next-gen hardware should stay ahead. DeepSeek is behind OpenAI’s o3 model but cooking with grease.
Parting thoughts…
The Chinese are giving the U.S. some competition… (this is a net good). They are a smart group with high avg. IQ and aren’t following the woke safety effective altruism bullshit you see with the “pause AI” and “stop AI” fools (these people fall into the “high IQ morons” category).
If a hedge fund is behind DeepSeek (in part) and they took a big short position against NVIDIA, they just made a fuck-ton of money so they can continue funding AI advancement (siphoning money away from the U.S. market)… if this was even their goal.
DeepSeek reached #1 on the U.S. iPhone App Store rankings and is extracting every crumb of data possible from developers and U.S. citizens. (This is what all AI companies are doing, including those in the U.S. But you should probably avoid giving your data to China).
Do NOT believe DeepSeek’s claims unless this can be replicated with the exact set-up they used: same data, hardware, etc. We need independent verification that they were able to actually pull this off before “taking their word for it.” The model is not yet “fully open” (despite what many parrot online).
Trump may opt to issue an EO allowing all U.S. AI companies to bypass copyright law for training. Chinese skip all copyright/IP laws… gives them an unfair advantage (zero time waste going through legal channels pre-training or fighting off lawyers while training).
In addition to skipping all copyright/IP laws, the Chinese are actively hacking proprietary software/code and other rarefied datasets. I won’t go into much detail here, but it should be obvious to anyone with half a brain.
The Chinese government may be subsidizing/backing DeepSeek in certain ways. They’d like nothing more than for DeepSeek to demoralize Americans and GPU investment/buying to decline while Huawei chips try to catch NVIDIA and SMIC tries to catch TSMC - and while their labs load up on more new chips. (The U.S. fell for the “psyop” regardless of whether intentional: people think the Chinese are superior in AI as opposed to the reality: IP thieves + optimizers).
The DeepSeek R1 model may help some U.S. AI Labs in certain ways (studying it, innovating upon it, etc.) but most have made a lot of advancements similar to this that haven’t been publicly released yet. This model cost a similar amount to Claude 3.5 Sonnet and is ~12 months late to the show.
The U.S. remains ~1 year ahead of China in AI. DeepSeek didn’t change this or expose much of anything. If any improvements can be extracted from DeepSeek, they may have helped U.S. labs get an even bigger lead.
AFAIK the training for DeepSeek is highly scalable such that: more GPUs = direct performance improvements. Diminishing returns were solved from PRM (Process Reward Model). Each additional GPU should yield proportional gains. (Should mean increased demand for NVIDIA GPUs, HBM, etc.)
U.S. AI Labs should ignore all the hype re: DeepSeek and probably do the opposite of what mainstream media thinks… they should be going H.A.M. stockpiling the latest NVIDIA GPU hardware, setting up superclusters, and continue what they’ve been doing (while implementing any cost-efficiency improvements they can from DeepSeek).